Pangkalan Data Elasticsearch
Elasticsearch adalah salah satu pangkalan data NoSQL yang paling popular yang digunakan untuk menyimpan dan mencari data berdasarkan teks. Ia didasarkan pada teknologi pengindeksan Lucene dan memungkinkan pengambilan carian dalam milisaat berdasarkan data yang diindeks.
Berdasarkan laman web Elasticsearch, berikut adalah definisi:
Elasticsearch adalah mesin carian dan analitik sumber terbuka yang diedarkan, RESTful mampu menyelesaikan banyak kes penggunaan.
Itu adalah kata-kata peringkat tinggi mengenai Elasticsearch. Mari kita fahami konsep secara terperinci di sini.
- Diagihkan: Elasticsearch membahagikan data yang terdapat dalam beberapa node dan kegunaan tuan-hamba algoritma secara dalaman
- TERBAIK: Elasticsearch menyokong pertanyaan pangkalan data melalui REST API. Ini bermaksud bahawa kita boleh menggunakan panggilan HTTP mudah dan menggunakan kaedah HTTP seperti GET, POST, PUT, DELETE dll. untuk mengakses data.
- Enjin carian dan Analitis: ES menyokong pertanyaan yang sangat analitis untuk dijalankan dalam sistem yang boleh terdiri daripada pertanyaan agregat dan pelbagai jenis, seperti pertanyaan berstruktur, tidak berstruktur dan geo.
- Berskala secara mendatar: Skailing semacam ini merujuk kepada menambahkan lebih banyak mesin ke kluster yang ada. Ini bermaksud bahawa ES mampu menerima lebih banyak node dalam klusternya dan tidak memberikan waktu henti untuk peningkatan yang diperlukan ke sistem. Lihat gambar di bawah untuk memahami konsep penskalaan:
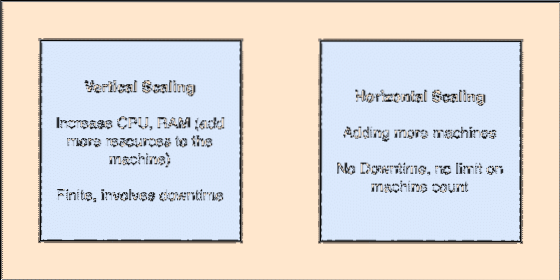
Skala menegak dan mendatar
Bermula dengan Pangkalan Data Elasticsearch
Untuk mula menggunakan Elasticsearch, alat itu mesti dipasang pada mesin. Untuk melakukan ini, baca Pasang Pencarian Elastik di Ubuntu.
Pastikan anda mempunyai pemasangan ElasticSearch yang aktif sekiranya anda ingin mencuba contoh yang kami sampaikan dalam pelajaran nanti.
Pencarian Elastik: Konsep & Komponen
Dalam bahagian ini, kita akan melihat komponen dan konsep apa yang terdapat di tengah-tengah Elasticsearch. Memahami konsep ini penting untuk memahami bagaimana ES berfungsi:
- Kluster: Kluster adalah kumpulan mesin pelayan (Node) yang menyimpan data. Data dibahagikan antara beberapa node sehingga dapat ditiru dan Titik Kegagalan Tunggal (SPoF) tidak berlaku dengan Pelayan ES. Nama lalai kluster adalah carian elastik. Setiap simpul dalam kluster menghubungkan ke kluster dengan URL dan nama kluster jadi penting untuk menjaga nama ini jelas dan jelas.
- Node: Mesin Node adalah sebahagian daripada pelayan dan diistilahkan sebagai mesin tunggal. Ia menyimpan data dan menyediakan kemampuan pengindeksan dan pencarian, bersama dengan Node lain ke kluster.
Oleh kerana konsep penskalaan Horizontal, kita dapat menambahkan bilangan simpul yang tidak terhingga dalam kluster ES untuk memberikan kekuatan dan kemampuan pengindeksan yang lebih banyak.
- Indeks: Indeks adalah kumpulan dokumen dengan ciri-ciri yang agak serupa. Indeks hampir sama dengan Pangkalan Data dalam persekitaran berasaskan SQL.
- Jenis: Jenis digunakan untuk memisahkan data antara indeks yang sama. Sebagai contoh, Pangkalan Data Pelanggan / Indeks boleh mempunyai pelbagai jenis, seperti pengguna, jenis_pembayaran dll.
Perhatikan bahawa Jenis tidak digunakan lagi dari ES v6.0.0 dan seterusnya. Baca di sini mengapa ini dilakukan.
- Dokumen: Dokumen adalah tahap unit terendah yang mewakili data. Bayangkan ia seperti Objek JSON yang mengandungi data anda. Adalah mungkin untuk mengindeks seberapa banyak dokumen di dalam Indeks.
Jenis carian di Elasticsearch
Elasticsearch terkenal dengan kemampuan mencari dalam masa nyata dan kelenturan yang diberikannya dengan jenis data yang diindeks dan dicari. Mari mulakan kajian bagaimana menggunakan carian dengan pelbagai jenis data.
- Carian Berstruktur: Jenis carian ini dijalankan pada data yang mempunyai format yang telah ditentukan seperti Tarikh, masa, dan nombor. Dengan format yang telah ditentukan, fleksibiliti menjalankan operasi biasa seperti membandingkan nilai dalam jarak tarikh. Menariknya, data teks juga dapat disusun. Ini boleh berlaku apabila medan mempunyai bilangan nilai yang tetap. Contohnya, Nama Pangkalan Data boleh, MySQL, MongoDB, Elasticsearch, Neo4J dll. Dengan carian berstruktur, jawapan untuk pertanyaan yang kami jalankan adalah ya atau tidak.
- Pencarian Teks Penuh: Jenis carian ini bergantung pada dua faktor penting, Perkaitan dan Analisis. Dengan Perkaitan, kami menentukan seberapa baik beberapa data sesuai dengan pertanyaan dengan menentukan skor pada dokumen yang dihasilkan. Skor ini disediakan oleh ES sendiri. Analisis merujuk kepada memecah teks menjadi token dinormalisasi untuk membuat indeks terbalik.
- Pencarian Multifield: Dengan jumlah pertanyaan analitik yang semakin meningkat pada data yang tersimpan di ES, kami biasanya tidak hanya menghadapi pertanyaan padanan sederhana. Keperluan telah berkembang untuk menjalankan pertanyaan yang merangkumi pelbagai bidang dan mempunyai senarai data yang disusun berdasarkan skor dikembalikan kepada kami oleh pangkalan data itu sendiri. Dengan cara ini, data dapat disampaikan kepada pengguna akhir dengan cara yang jauh lebih efisien.
- Proimity Matching: Pertanyaan hari ini lebih daripada sekadar mengenal pasti sama ada beberapa data teks mengandungi rentetan lain atau tidak. Ini mengenai menjalin hubungan antara data sehingga dapat dinilai dan dipadankan dengan konteks di mana data dicocokkan. Sebagai contoh:
- Bola memukul John
- John memukul Bola
- John membeli Bola baru yang dilanda kebun Jaen
Pertanyaan padanan akan menemui ketiga-tiga dokumen ketika dicari Pukul bola. Pencarian jarak dekat dapat memberitahu kami sejauh mana kedua kata ini muncul dalam baris atau perenggan yang sama kerana kata-kata itu sesuai.
- Pemadanan Separa: Selalunya kita perlu menjalankan pertanyaan sepadan dengan sepadan. Pemadanan Separa membolehkan kita menjalankan pertanyaan yang sepadan dengan sebahagiannya. Untuk menggambarkan ini, mari kita lihat pertanyaan berdasarkan SQL yang serupa:
Pertanyaan SQL: Pemadanan Separa
DI MANA nama SEPERTI "% john%"
DAN namakan SEPERTI "% red%"
DAN namakan SEPERTI "% garden%"Pada beberapa kesempatan, kita hanya perlu menjalankan pertanyaan sepadan walaupun mereka boleh dianggap seperti teknik brute-force.
Integrasi dengan Kibana
Ketika datang ke mesin analisis, kita biasanya perlu menjalankan pertanyaan analisis dalam domain Business-Intelligence (BI). Apabila berkaitan dengan Penganalisis Perniagaan atau Penganalisis Data, tidak adil untuk menganggap bahawa orang tahu bahasa pengaturcaraan ketika mereka ingin memvisualisasikan data yang ada di ES Cluster. Masalah ini diselesaikan oleh Kibana. Kibana menawarkan begitu banyak faedah kepada BI sehingga orang dapat benar-benar memvisualisasikan data dengan papan pemuka yang sangat baik dan dapat disesuaikan dan melihat data secara tidak praktikal. Mari lihat beberapa faedahnya di sini.
Carta Interaktif
Inti Kibana ialah Carta Interaktif seperti berikut: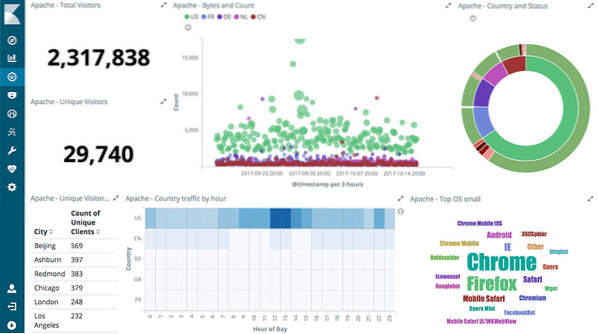
Kibana disokong dengan pelbagai jenis carta seperti carta pai, cahaya matahari, histogram dan banyak lagi yang menggunakan keupayaan agregasi lengkap ES.
Sokongan Pemetaan
Kibana juga menyokong Pengumpulan Geografis lengkap yang membolehkan kami memetakan data geo. Bukankah ini sejuk?!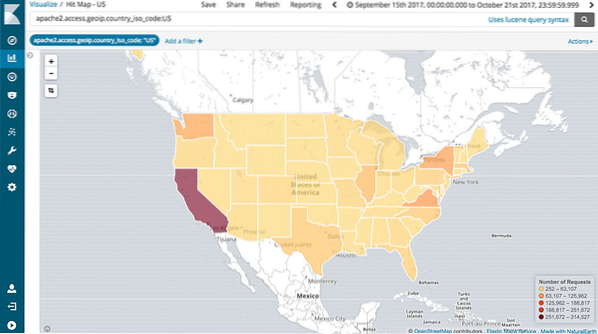
Gabungan dan Penapis yang telah dibina sebelumnya
Dengan Pengumpulan dan Penapis Pra-Bina, adalah mungkin untuk memecah, melepaskan dan menjalankan pertanyaan yang sangat dioptimumkan dalam Papan Pemuka Kibana. Dengan hanya beberapa klik, adalah mungkin untuk menjalankan pertanyaan gabungan dan memberikan hasil dalam bentuk Carta Interaktif.
Pengagihan Papan Pemuka yang Mudah
Dengan Kibana, sangat senang untuk berkongsi papan pemuka kepada khalayak yang jauh lebih luas tanpa melakukan perubahan pada papan pemuka dengan bantuan mod Dashboard Only. Kami boleh memasukkan papan pemuka ke dalam wiki dalaman atau laman web kami dengan mudah.
Imej ciri diambil dari halaman Produk Kibana.
Menggunakan Elasticsearch
Untuk melihat perincian contoh dan maklumat kluster, jalankan perintah berikut: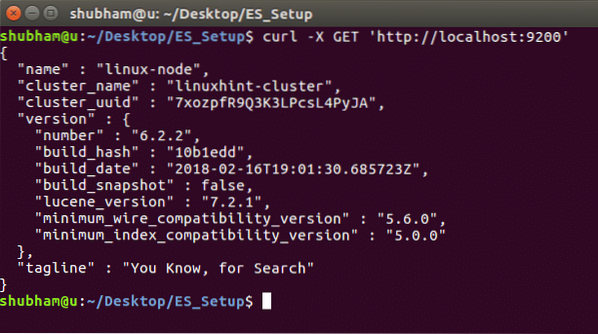
Sekarang, kita boleh mencuba memasukkan beberapa data ke dalam ES menggunakan perintah berikut:
Memasukkan Data
keriting \-X POST 'http: // localhost: 9200 / linuxhint / hello / 1' \
-H 'Kandungan-Jenis: aplikasi / json' \
-d '"name": "LinuxHint"' \
Inilah yang kita dapat kembali dengan arahan ini:
Mari cuba dapatkan data sekarang:
Mendapatkan Data
curl -X DAPATKAN 'http: // localhost: 9200 / linuxhint / hello / 1'Apabila kita menjalankan perintah ini, kita mendapat output berikut:
Kesimpulannya
Dalam pelajaran ini, kami melihat bagaimana kami dapat mula menggunakan ElasticSearch yang merupakan Mesin Analisis yang sangat baik dan memberikan sokongan yang sangat baik untuk carian teks bebas masa nyata juga.


