Apache Spark adalah alat analisis data yang dapat digunakan untuk memproses data dari HDFS, S3 atau sumber data lain dalam memori. Dalam catatan ini, kami akan memasang Apache Spark pada Ubuntu 17.10 mesin.
Versi Ubuntu
Untuk panduan ini, kami akan menggunakan Ubuntu versi 17.10 (GNU / Linux 4.13.0-38-generik x86_64).
Apache Spark adalah bahagian dari ekosistem Hadoop untuk Big Data. Cuba Pasang Apache Hadoop dan buat contoh aplikasi dengannya.
Mengemas kini pakej yang ada
Untuk memulakan pemasangan Spark, kita perlu mengemas kini mesin kita dengan pakej perisian terkini yang tersedia. Kita boleh melakukan ini dengan:
sudo apt-get kemas kini && sudo apt-get -y dist-upgradeOleh kerana Spark menggunakan Java, kita perlu memasangnya di mesin kita. Kita dapat menggunakan versi Java apa pun di atas Java 6. Di sini, kita akan menggunakan Java 8:
sudo apt-get -y install openjdk-8-jdk-tanpa kepalaMemuat turun fail Spark
Semua pakej yang diperlukan kini ada di mesin kami. Kami bersedia memuat turun fail Spark TAR yang diperlukan supaya kami dapat memulakannya dan menjalankan program contoh dengan Spark juga.
Dalam panduan ini, kami akan memasang Percikan v2.3.0 terdapat di sini:
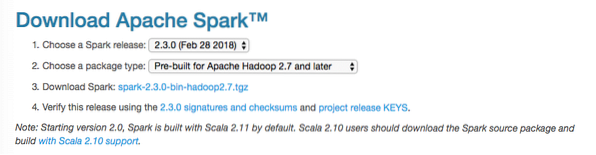
Halaman muat turun percikan
Muat turun fail yang sesuai dengan arahan ini:
wget http: // www-kami.apache.org / dist / percikan / percikan api-2.3.0 / percikan-2.3.0-bin-hadoop2.7.tgzBergantung pada kelajuan rangkaian, ini memerlukan beberapa minit kerana ukuran failnya besar:
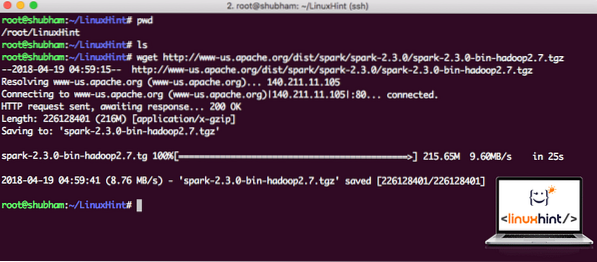
Memuat turun Apache Spark
Setelah fail TAR dimuat turun, kita dapat mengekstrak dalam direktori semasa:
tar xvzf spark-2.3.0-bin-hadoop2.7.tgzProses ini akan mengambil masa beberapa saat kerana ukuran fail yang besar dari arkib:
Fail yang tidak diarkibkan di Spark
Ketika datang ke peningkatan Apache Spark di masa depan, ia dapat menimbulkan masalah kerana kemas kini Path. Masalah-masalah ini dapat dielakkan dengan membuat softlink ke Spark. Jalankan arahan ini untuk membuat pautan lembut:
ln -s percikan api-2.3.0-bin-hadoop2.7 percikanMenambah Spark ke Laluan
Untuk melaksanakan skrip Spark, kami akan menambahkannya ke jalan sekarang. Untuk melakukan ini, buka fail bashrc:
vi ~ /.bashrcTambahkan baris ini ke hujung .fail bashrc sehingga jalan boleh mengandungi jalur fail yang dapat dilaksanakan Spark:
SPARK_HOME = / LinuxHint / percikaneksport PATH = $ SPARK_HOME / tong: $ PATH
Sekarang, failnya seperti:
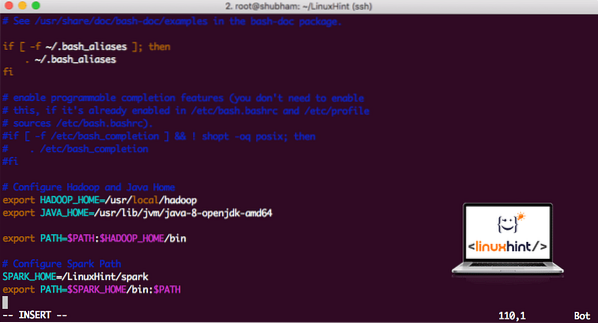
Menambah Spark ke PATH
Untuk mengaktifkan perubahan ini, jalankan perintah berikut untuk fail bashrc:
sumber ~ /.bashrcMelancarkan Spark Shell
Sekarang apabila kita berada tepat di luar direktori percikan, jalankan perintah berikut untuk membuka shell apark:
./ percikan / tong / percikan apiKami akan melihat bahawa Spark shell terbuka sekarang:
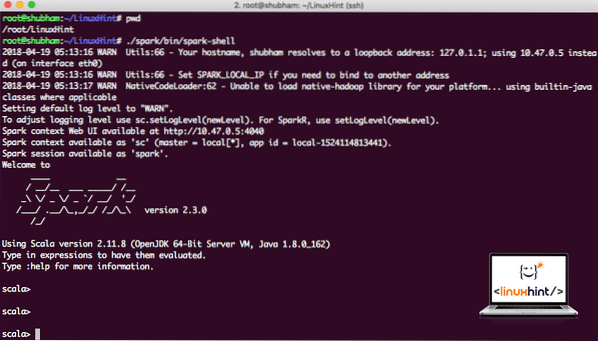
Melancarkan shell Spark
Kita dapat melihat di konsol bahawa Spark juga telah membuka Konsol Web di port 404. Mari kita lawati:
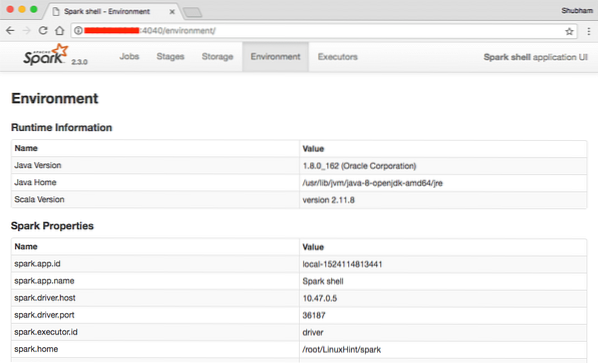
Konsol Web Apache Spark
Walaupun kami akan beroperasi di konsol itu sendiri, lingkungan web adalah tempat penting untuk dilihat ketika Anda menjalankan Pekerjaan Spark berat sehingga Anda tahu apa yang terjadi dalam setiap Pekerjaan Spark yang Anda laksanakan.
Periksa versi shell Spark dengan arahan mudah:
sc.versiKami akan mendapat kembali seperti:
res0: Rentetan = 2.3.0Membuat contoh Aplikasi Spark dengan Scala
Sekarang, kami akan membuat contoh aplikasi Word Counter dengan Apache Spark. Untuk melakukan ini, muatkan fail teks ke Spark Context pada Spark shell terlebih dahulu:
scala> var Data = sc.textFile ("/ root / LinuxHint / spark / README.md ")Data: org.apache.percikan api.rdd.RDD [String] = / root / LinuxHint / spark / README.md MapPartitionsRDD [1] di textFile pada: 24
scala>
Sekarang, teks yang ada dalam fail mesti dipecah menjadi token yang dapat diuruskan oleh Spark:
scala> token var = Data.peta rata (s => s.berpecah (""))token: org.apache.percikan api.rdd.RDD [String] = MapPartitionsRDD [2] di flatMap pada: 25
scala>
Sekarang, mulakan kiraan untuk setiap perkataan menjadi 1:
scala> var tokens_1 = token.peta (s => (s, 1))token_1: org.apache.percikan api.rdd.RDD [(String, Int)] = MapPartitionsRDD [3] pada peta di: 25
scala>
Akhirnya, hitung kekerapan setiap perkataan fail:
var sum_each = tokens_1.kurangkanByKey ((a, b) => a + b)Masa untuk melihat output program. Kumpulkan token dan jumlahnya:
scala> sum_each.kumpulkan ()res1: Array [(String, Int)] = Array ((pakej, 1), (Untuk, 3), (Program, 1), (memproses.,1), (Kerana, 1), (The, 1), (halaman] (http: // percikan.apache.org / dokumentasi.html).,1), (kelompok.,1), (itu, 1), ([jalankan, 1), (daripada, 1), (API, 1), (mempunyai, 1), (Cuba, 1), (pengiraan, 1), (hingga, 1 ), (beberapa, 1), (Ini, 2), (grafik, 1), (Sarang, 2), (penyimpanan, 1), (["Menentukan, 1), (Kepada, 2), (" benang " , 1), (Sekali, 1), (["Berguna, 1), (lebih suka, 1), (SparkPi, 2), (mesin, 1), (versi, 1), (fail, 1), (dokumentasi ,, 1), (pemprosesan ,, 1), (the, 24), (are, 1), (sistem.,1), (params, 1), (bukan, 1), (berbeza, 1), (rujuk, 2), (Interaktif, 2), (R ,, 1), (diberikan.,1), (jika, 4), (bina, 4), (kapan, 1), (menjadi, 2), (Ujian, 1), (Apache, 1), (utas, 1), (program ,, 1 ), (termasuk, 4), (./ bin / run-contoh, 2), (Spark.,1), (pakej.,1), (1000).hitung (), 1), (Versi, 1), (HDFS, 1), (D ..
scala>
Cemerlang! Kami dapat menjalankan contoh Word Counter sederhana dengan menggunakan bahasa pengaturcaraan Scala dengan fail teks yang sudah ada dalam sistem.
Kesimpulannya
Dalam pelajaran ini, kami melihat bagaimana kami dapat memasang dan mula menggunakan Apache Spark di Ubuntu 17.10 mesin dan jalankan contoh aplikasi di atasnya juga.
Baca lebih banyak catatan berasaskan Ubuntu di sini.


