Dalam pelajaran ini mengenai Pembelajaran Mesin dengan belajar sedikit, kita akan mempelajari pelbagai aspek dari pakej Python yang sangat baik ini yang membolehkan kita menerapkan kemampuan Pembelajaran Mesin yang ringkas dan kompleks pada sekumpulan data yang beragam bersama dengan fungsi untuk menguji hipotesis yang kita buat.
Pakej scikit-learning mengandungi alat yang mudah dan cekap untuk menerapkan perlombongan data dan analisis data pada set data dan algoritma ini tersedia untuk diterapkan dalam konteks yang berbeza. Ini adalah pakej sumber terbuka yang terdapat di bawah lesen BSD, yang bermaksud bahawa kita dapat menggunakan perpustakaan ini walaupun secara komersial. Ia dibina di atas matplotlib, NumPy dan SciPy sehingga sifatnya serba boleh. Kami akan menggunakan buku nota Anaconda dengan Jupyter untuk memberikan contoh dalam pelajaran ini.
Apa yang disediakan oleh scikit-learning?
Perpustakaan scikit-learning memberi tumpuan sepenuhnya kepada pemodelan data. Harap maklum bahawa tidak ada fungsi utama dalam scikit-learning ketika memuat, memanipulasi dan meringkaskan data. Berikut adalah beberapa model popular yang disediakan oleh scikit-learning kepada kami:
- Penggabungan untuk mengelompokkan data berlabel
- Set data untuk menyediakan set data ujian dan menyiasat tingkah laku model
- Pengesahan bersilang untuk menganggar prestasi model yang diselia pada data yang tidak dapat dilihat
- Kaedah ensemble untuk menggabungkan ramalan pelbagai model yang diselia
- Pengekstrakan ciri untuk menentukan atribut dalam gambar dan data teks
Pasang Python scikit-learn
Sekadar catatan sebelum memulakan proses pemasangan, kami menggunakan persekitaran maya untuk pelajaran ini yang kami buat dengan arahan berikut:
python -m virtualenv scikitsumber scikit / bin / aktifkan
Setelah persekitaran maya aktif, kita dapat memasang perpustakaan panda dalam env maya sehingga contoh yang kita buat seterusnya dapat dilaksanakan:
pip memasang scikit-belajarAtau, kita boleh menggunakan Conda untuk memasang pakej ini dengan arahan berikut:
conda pasang scikit-belajarKami melihat sesuatu seperti ini semasa kami melaksanakan perintah di atas:

Setelah pemasangan selesai dengan Conda, kami akan dapat menggunakan pakej dalam skrip Python kami sebagai:
import sklearnMari mulakan penggunaan scikit-learning dalam skrip kami untuk mengembangkan algoritma Pembelajaran Mesin yang hebat.
Mengimport Set Data
Salah satu perkara yang menarik dengan scikit-learning ialah ia dilengkapi dengan data set sampel yang mudah dimulakan dengan cepat. Set data adalah iris dan digit set data untuk klasifikasi dan harga rumah boston dataset untuk teknik regresi. Di bahagian ini, kita akan melihat bagaimana memuat dan mula menggunakan set data iris.
Untuk mengimport set data, pertama-tama kita harus mengimport modul yang betul diikuti dengan menahan pada set data:
dari set data import sklearniris = set data.load_iris ()
digit = set data.muat_digit ()
digit.data
Setelah kami menjalankan coretan kod di atas, kami akan melihat output berikut:

Semua output dikeluarkan kerana singkat. Ini adalah dataset yang akan banyak kita gunakan dalam pelajaran ini tetapi kebanyakan konsep dapat diterapkan pada umumnya semua set data.
Hanya satu fakta yang menyeronokkan untuk mengetahui bahawa terdapat banyak modul yang terdapat di scikit ekosistem, salah satunya adalah belajar digunakan untuk algoritma Pembelajaran Mesin. Lihat halaman ini untuk banyak modul lain yang ada.
Meneroka Set Data
Setelah kita mengimport set data digit yang disediakan ke dalam skrip kita, kita harus mula mengumpulkan maklumat asas mengenai set data dan itulah yang akan kita lakukan di sini. Berikut adalah perkara asas yang harus anda terokai sambil mencari maklumat mengenai set data:
- Nilai atau label sasaran
- Atribut keterangan
- Kekunci yang terdapat dalam set data yang diberikan
Mari kita tulis coretan kod pendek untuk mengekstrak tiga maklumat di atas dari set data kami:
cetak ('Target:', digit.sasaran)cetak ('Kekunci:', digit.kunci ())
cetak ('Penerangan:', digit.PENERANGAN)
Setelah kami menjalankan coretan kod di atas, kami akan melihat output berikut:
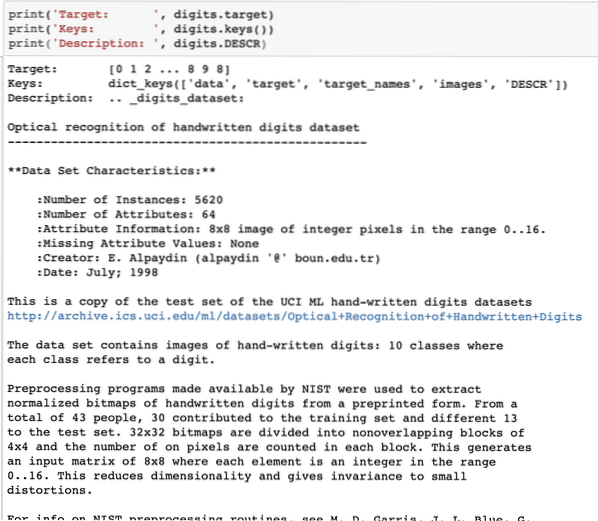
Harap maklum bahawa digit pemboleh ubah tidak mudah. Semasa kami mencetak set data digit, sebenarnya mengandungi susunan numpy. Kami akan melihat bagaimana kami dapat mengakses tatasusunan ini. Untuk ini, perhatikan kunci yang terdapat dalam contoh digit yang kami cetak dalam coretan kod terakhir.
Kami akan bermula dengan mendapatkan bentuk data array, yang merupakan baris dan lajur yang dimiliki array. Untuk ini, pertama kita perlu mendapatkan data sebenar dan kemudian mendapatkan bentuknya:
digit_set = digit.datacetak (digit_set.bentuk)
Setelah kami menjalankan coretan kod di atas, kami akan melihat output berikut:

Ini bermakna terdapat 1797 sampel dalam kumpulan data kami bersama dengan 64 ciri data (atau lajur). Kami juga mempunyai beberapa label sasaran yang akan kami gambarkan di sini dengan bantuan matplotlib. Berikut adalah coretan kod yang membantu kami melakukannya:
import matplotlib.pyplot sebagai plt# Gabungkan gambar dan label sasaran sebagai senarai
images_and_labels = senarai (zip (digit).gambar, digit.sasaran))
untuk indeks, (gambar, label) dalam jumlah (gambar_dan label [: 8]):
# mulakan subplot 2X4 pada kedudukan i + 1-th
plt.subplot (2, 4, indeks + 1)
# Tidak perlu membuat sumbu
plt.paksi ('mati')
# Tunjukkan gambar di semua subplot
plt.imshow (gambar, cmap = plt.cm.grey_r, interpolasi = 'terdekat')
# Tambahkan tajuk untuk setiap subplot
plt.tajuk ('Latihan:' + str (label))
plt.tunjuk ()
Setelah kami menjalankan coretan kod di atas, kami akan melihat output berikut:

Perhatikan bagaimana kita menyatukan dua tatasusunan NumPy sebelum meletakkannya ke grid 4 hingga 2 tanpa maklumat paksi. Sekarang, kami pasti mengenai maklumat yang kami ada mengenai set data yang kami bekerjasama.
Sekarang kita tahu bahawa kita mempunyai 64 ciri data (yang banyak fiturnya), sangat sukar untuk memvisualisasikan data sebenarnya. Kami ada jalan keluar untuk ini.
Analisis Komponen Utama (PCA)
Ini bukan tutorial mengenai PCA, tetapi mari kita memberikan idea kecil tentang apa itu. Seperti yang kita ketahui bahawa untuk mengurangkan bilangan ciri dari set data, kita mempunyai dua teknik:
- Penghapusan Ciri
- Pengekstrakan Ciri
Walaupun teknik pertama menghadapi masalah ciri data yang hilang walaupun mungkin penting, teknik kedua tidak mengalami masalah kerana dengan bantuan PCA, kami membina ciri data baru (kurang bilangannya) di mana kami menggabungkan masukan pemboleh ubah sedemikian rupa, sehingga kita dapat meninggalkan pemboleh ubah "paling tidak penting" sambil tetap mengekalkan bahagian yang paling berharga dari semua pemboleh ubah.
Seperti yang dijangkakan, PCA membantu kami mengurangkan dimensi tinggi data yang merupakan hasil langsung dari menggambarkan objek menggunakan banyak ciri data. Bukan hanya digit tetapi banyak set data praktikal lain mempunyai banyak ciri yang merangkumi data institusi kewangan, data cuaca dan ekonomi untuk wilayah dll. Semasa kita melakukan PCA pada set data digit, tujuan kami adalah untuk mencari hanya 2 ciri yang mempunyai kebanyakan ciri set data.
Mari tulis coretan kod mudah untuk menggunakan PCA pada set data digit untuk mendapatkan model linear kami dengan hanya 2 ciri:
dari sklearn.PCA import penguraianfeature_pca = PCA (n_komponen = 2)
dikurangkan_data_random = feature_pca.fit_transform (digit.data)
model_pca = PCA (n_komponen = 2)
dikurangkan_data_pca = model_pca.fit_transform (digit.data)
dikurangkan_data_pca.bentuk
cetak (dikurangkan_data_rawak)
cetak (dikurangkan_data_pca)
Setelah kami menjalankan coretan kod di atas, kami akan melihat output berikut:
[[-1.2594655 21.27488324][7.95762224 -20.76873116]
[6.99192123 -9.95598191]
…
[10.8012644 -6.96019661]
[-4.87210598 12.42397516]
[-0.34441647 6.36562581]]
[[-1.25946526 21.27487934]
[7.95761543 -20.76870705]
[6.99191947 -9.9559785]
…
[10.80128422 -6.96025542]
[-4.87210144 12.42396098]
[-0.3443928 6.36555416]]
Dalam kod di atas, kami menyebutkan bahawa kami hanya memerlukan 2 ciri untuk set data.
Sekarang kerana kami mempunyai pengetahuan yang baik mengenai set data kami, kami dapat memutuskan jenis algoritma pembelajaran mesin yang dapat kami gunakan di atasnya. Mengetahui set data adalah penting kerana dengan cara itulah kita dapat menentukan maklumat apa yang dapat diekstrak daripadanya dan dengan algoritma mana. Ini juga membantu kita menguji hipotesis yang kita buat sambil meramalkan nilai masa depan.
Mengaplikasikan pengelompokan k-bermaksud
Algoritma kluster k-bermaksud adalah salah satu algoritma pengelompokan termudah untuk pembelajaran tanpa pengawasan. Dalam pengelompokan ini, kami mempunyai beberapa kelompok yang rawak dan kami mengklasifikasikan titik data kami dalam satu kelompok tersebut. Algoritma k-means akan mencari kluster terdekat untuk setiap titik data yang diberikan dan memberikan titik data itu ke kluster itu.
Setelah pengelompokan selesai, pusat kluster dikira semula, titik data diberikan kluster baru jika ada perubahan. Proses ini diulang sehingga titik data berhenti berubah di sana untuk mencapai kestabilan.
Mari kita gunakan algoritma ini tanpa proses awal data. Untuk strategi ini, coretan kod akan cukup mudah:
dari kelompok import sklearnk = 3
k_means = kelompok.KMeans (k)
# data muat
k_maksud.sesuai (digit.data)
# hasil cetak
cetak (k_means.label _ [:: 10])
mencetak (digit.sasaran [:: 10])
Setelah kami menjalankan coretan kod di atas, kami akan melihat output berikut:
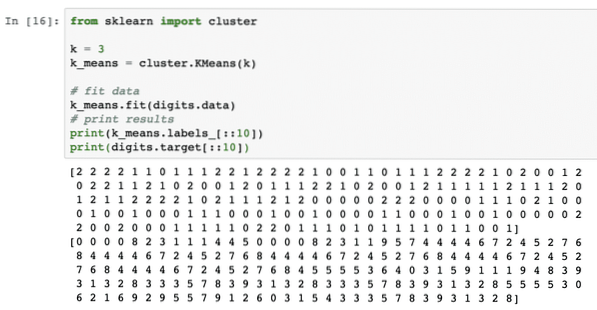
Dalam output di atas, kita dapat melihat kluster yang berbeza disediakan untuk setiap titik data.
Kesimpulannya
Dalam pelajaran ini, kami melihat perpustakaan Machine Learning yang sangat baik, scikit-learning. Kami mengetahui bahawa terdapat banyak modul lain yang terdapat dalam keluarga scikit dan kami menggunakan algoritma k-means sederhana pada set data yang disediakan. Terdapat banyak lagi algoritma yang dapat diterapkan pada set data selain pengelompokan k-means yang kami terapkan dalam pelajaran ini, kami mendorong anda untuk melakukannya dan berkongsi hasil anda.
Sila kongsi maklum balas anda mengenai pelajaran di Twitter dengan @sbmaggarwal dan @LinuxHint.


