Harap maklum bahawa ini bukan pelajaran pengantar. Sila baca Apa itu Apache Kafka dan bagaimana cara kerjanya sebelum anda meneruskan pelajaran ini untuk mendapatkan pandangan yang lebih mendalam.
Topik di Kafka
Topik dalam Kafka adalah sesuatu di mana mesej dihantar. Aplikasi pengguna yang berminat dengan topik itu menarik mesej ke dalam topik itu dan dapat melakukan apa sahaja dengan data tersebut. Hingga waktu tertentu, sejumlah aplikasi pengguna dapat menarik pesan ini berkali-kali.
Pertimbangkan Topik seperti halaman Blog Ubuntu LinuxHint. Pelajaran itu dilanjutkan hingga selamanya dan sebilangan besar pembaca yang bersemangat dapat datang dan membaca pelajaran ini berkali-kali atau beralih ke pelajaran seterusnya yang mereka inginkan. Pembaca ini juga boleh berminat dengan topik lain dari LinuxHint juga.
Pemisahan Topik
Kafka direka untuk menguruskan aplikasi berat dan mengantri sebilangan besar mesej yang disimpan di dalam topik. Untuk memastikan toleransi kesalahan tinggi, setiap Topik dibahagikan kepada beberapa partisi topik dan setiap Partisi Topik diuruskan pada nod yang berasingan. Sekiranya salah satu node turun, node lain dapat bertindak sebagai peneraju topik dan dapat melayan topik kepada pengguna yang berminat. Berikut adalah bagaimana data yang sama ditulis untuk beberapa Partisi Topik: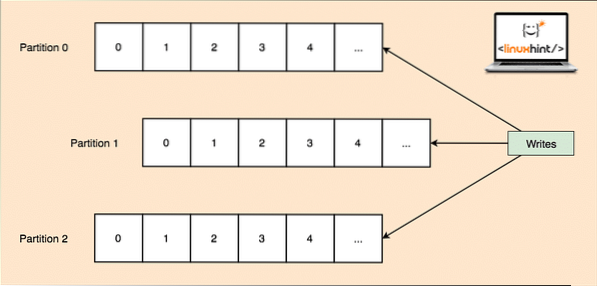
Pembahagian Topik
Sekarang, gambar di atas menunjukkan bagaimana data yang sama ditiru di beberapa bahagian. Mari kita gambarkan bagaimana partisi yang berbeza dapat bertindak sebagai pemimpin pada nod / partisi yang berbeza:
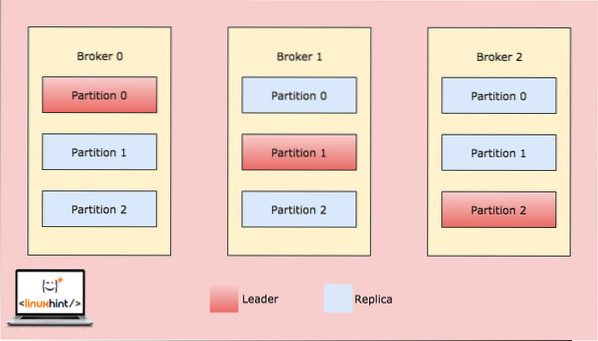
Pembahagian Broker Kafka
Apabila pelanggan menulis sesuatu ke topik pada kedudukan yang Partition di Broker 0 adalah pemimpin, data ini kemudian direplikasi di seluruh broker / node sehingga mesej tetap selamat: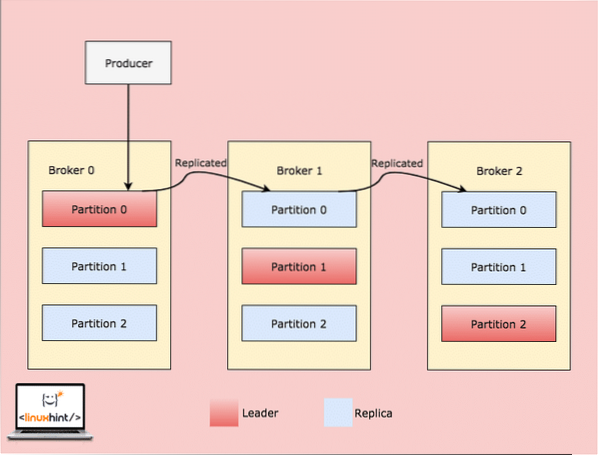
Replikasi merentasi Parti Broker
Lebih Banyak Bahagian, Hasil yang Lebih Tinggi
Kafka menggunakan Paralelisme untuk memberikan throughput yang sangat tinggi kepada aplikasi pengeluar dan pengguna. Sebenarnya, dengan cara yang sama, ia juga mengekalkan statusnya sebagai sistem toleransi kesalahan tinggi. Mari kita fahami sejauh mana throughput yang tinggi dicapai dengan Parallelism.
Apabila aplikasi Producer menulis beberapa mesej ke Partition di Broker 0, Kafka membuka banyak utas secara selari sehingga mesej dapat ditiru di semua Broker yang dipilih pada masa yang sama. Di sisi Pengguna, aplikasi pengguna menggunakan mesej dari satu partisi melalui utas. Semakin banyak partisi, semakin banyak utas pengguna dapat dibuka sehingga semuanya dapat berfungsi secara selari juga. Ini bermakna semakin banyak bilangan partisi dalam kluster, semakin paralelisme dapat dieksploitasi, mewujudkan sistem throughput yang sangat tinggi.
Lebih banyak Partisi memerlukan lebih banyak Pengendali Fail
Untuk mengetahui bagaimana kami dapat meningkatkan prestasi sistem Kafka dengan hanya meningkatkan jumlah partisi. Tetapi kita harus berhati-hati dengan had apa yang sedang kita lalui.
Setiap Partisi Topik di Kafka dipetakan ke direktori dalam sistem fail broker Server tempat ia dijalankan. Di dalam direktori log tersebut, akan ada dua fail: satu untuk indeks dan satu lagi untuk data sebenar setiap segmen log. Pada masa ini, di Kafka, setiap broker membuka pemegang fail untuk indeks dan fail data dari setiap segmen log. Ini bermakna bahawa jika anda mempunyai 10,000 Partition pada satu Broker, ini akan menyebabkan 20,000 Pengendali Fail berjalan secara selari. Walaupun, ini hanya mengenai konfigurasi Broker. Sekiranya sistem yang digunakan oleh Broker mempunyai konfigurasi yang tinggi, ini tidak akan menjadi masalah.
Berisiko dengan jumlah Partition yang tinggi
Seperti yang kita lihat dalam gambar di atas, Kafka menggunakan teknik replikasi intra-kluster untuk meniru mesej dari pemimpin ke partisi Replika yang terdapat di Broker lain. Kedua-dua aplikasi pengeluar dan pengguna membaca dan menulis ke partisi yang kini menjadi peneraju partisi tersebut. Apabila broker gagal, peneraju Broker tersebut tidak akan tersedia. Metadata mengenai siapa pemimpin disimpan di Zookeeper. Berdasarkan metadata ini, Kafka secara automatik akan menetapkan kepemimpinan partisi ke partisi lain.
Apabila Broker ditutup dengan perintah bersih, simpul pengawal kluster Kafka akan menggerakkan pemimpin broker penutupan secara bersiri.e. satu demi satu. jika kita mempertimbangkan untuk memindahkan pemimpin tunggal mengambil masa 5 milisaat, ketiadaan pemimpin tidak akan mengganggu pengguna kerana ketiadaan adalah untuk jangka waktu yang sangat singkat. Tetapi jika kita mempertimbangkan ketika Broker dibunuh dengan cara yang tidak bersih dan Broker ini mengandungi 5000 partisi dan dari jumlah tersebut, 2000 adalah pemimpin partisi, menetapkan pemimpin baru untuk semua partisi ini akan mengambil masa 10 saat yang sangat tinggi ketika datang ke sangat aplikasi dalam permintaan.
Kesimpulannya
Sekiranya kita menganggap sebagai pemikir peringkat tinggi, lebih banyak partisi dalam kluster Kafka membawa kepada throughput sistem yang lebih tinggi. Mengingat kecekapan ini, kita juga harus mempertimbangkan konfigurasi kluster Kafka yang perlu kita pertahankan, memori yang perlu kita tetapkan pada kluster itu dan bagaimana kita dapat menguruskan ketersediaan dan kependaman jika ada yang tidak kena.
Baca lebih banyak catatan berasaskan Ubuntu di sini dan banyak lagi mengenai Apache kafka juga.


