Apache Kafka
Untuk definisi peringkat tinggi, mari kita kemukakan definisi ringkas untuk Apache Kafka:
Apache Kafka adalah log komited yang diedarkan, bertolak ansur, dapat dilengkapkan secara mendatar.
Itu adalah beberapa kata tingkat tinggi mengenai Apache Kafka. Mari kita fahami konsep secara terperinci di sini.
- Diagihkan: Kafka membahagikan data yang dikandungnya ke dalam beberapa pelayan dan setiap pelayan ini mampu menangani permintaan dari klien untuk bahagian data yang dikandungnya
- Bertolak ansur dengan kesalahan: Kafka tidak mempunyai satu Titik Kegagalan. Dalam sistem SPoF, seperti pangkalan data MySQL, jika pelayan yang mengehadkan pangkalan data turun, aplikasi akan disekat. Dalam sistem yang tidak mempunyai SPoF dan terdiri daripada node berbilang, walaupun sebahagian besar sistem turun, masih sama untuk pengguna akhir.
- Berskala secara mendatar: Skailing semacam ini merujuk kepada menambahkan lebih banyak mesin ke kluster yang ada. Ini bermaksud bahawa Apache Kafka mampu menerima lebih banyak node dalam klusternya dan tidak memberikan waktu henti untuk peningkatan yang diperlukan ke sistem. Lihat gambar di bawah untuk memahami jenis konsep skailing:
- Komit Log: Log komit adalah Struktur Data seperti Senarai Terpaut. Ini menambahkan apa sahaja mesej yang datang kepadanya dan selalu menjaga pesanan mereka. Data tidak dapat dihapus dari log ini sehingga masa yang ditentukan dicapai untuk data tersebut.
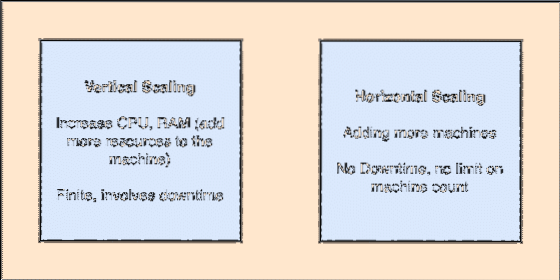
Skala menegak dan mendatar
Topik di Apache Kafka sama seperti barisan di mana mesej disimpan. Mesej ini disimpan untuk jangka waktu yang dapat dikonfigurasi dan mesej tidak akan dihapus sehingga waktu ini tercapai, walaupun ia telah dimakan oleh semua pengguna yang diketahui.
Kafka boleh diskalakan kerana pengguna yang sebenarnya menyimpan mesej apa yang diambil oleh mereka sebagai nilai 'offset'. Mari lihat tokoh untuk memahami perkara ini dengan lebih baik: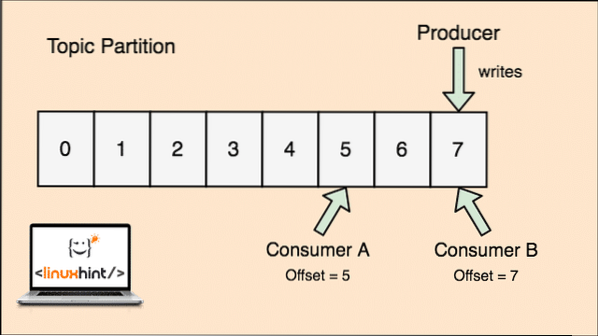
Bahagian topik dan Pengimbangan pengguna di Apache Kafka
Bermula dengan Apache Kafka
Untuk mula menggunakan Apache Kafka, ia mesti dipasang pada mesin. Untuk melakukan ini, baca Pasang Apache Kafka di Ubuntu.
Pastikan anda mempunyai pemasangan Kafka yang aktif jika anda ingin mencuba contoh yang kami sampaikan dalam pelajaran nanti.
Bagaimanakah ia berfungsi?
Dengan Kafka, yang Penerbit aplikasi menerbitkan mesej yang tiba di Kafka Node dan tidak terus kepada Pengguna. Dari Kafka Node ini, mesej digunakan oleh Pengguna aplikasi.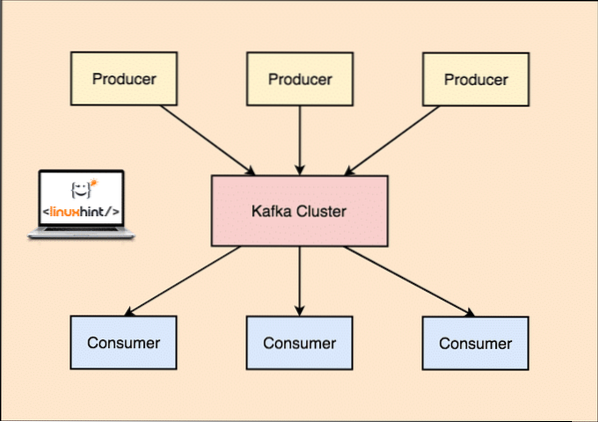
Pengeluar dan Pengguna Kafka
Oleh kerana satu topik dapat memperoleh banyak data sekaligus, untuk memastikan Kafka dapat ditingkatkan secara mendatar, setiap topik dibahagikan kepada partition dan setiap partisi boleh hidup di mana-mana mesin nod kluster. Mari kita cuba membentangkannya:
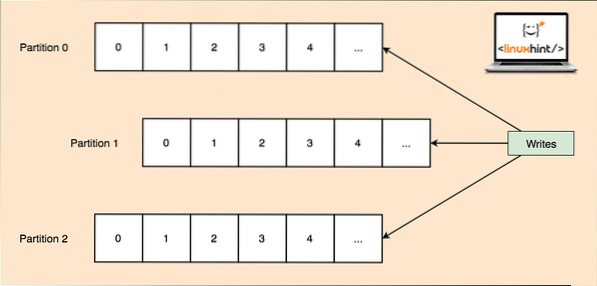
Pembahagian Topik
Sekali lagi, Kafka Broker tidak menyimpan rekod pengguna mana yang telah menggunakan berapa banyak paket data. Ia adalah tanggungjawab pengguna untuk memantau data yang telah digunakannya.
Ketekunan ke Cakera
Kafka tetap menyimpan rakaman mesej yang dikeluarkannya dari Producer pada cakera dan tidak menyimpannya dalam ingatan. Satu persoalan yang mungkin timbul adalah bagaimana hal ini membuat sesuatu dapat dilaksanakan dan cepat? Terdapat beberapa sebab di sebalik ini yang menjadikannya kaedah optimum dalam menguruskan rekod mesej:
- Kafka mengikuti protokol pengelompokan rekod mesej. Pengeluar menghasilkan mesej yang disimpan ke cakera dalam potongan besar dan pengguna menggunakan rakaman pesanan ini dalam potongan linier besar juga.
- Sebab penulisan cakera adalah linear, adalah kerana ini menjadikan pembacaan menjadi cepat kerana waktu membaca cakera linear yang sangat menurun.
- Operasi cakera linear dioptimumkan oleh Sistem operasi juga dengan menggunakan teknik tulis-belakang dan baca-hadapan.
- OS moden juga menggunakan konsep Pagecaching yang bermaksud bahawa mereka menyimpan beberapa data cakera dalam RAM yang tersedia secara percuma.
- Oleh kerana Kafka menyimpan data dalam data standard yang seragam di seluruh aliran dari pengeluar hingga pengguna, data tersebut menggunakan pengoptimuman salinan sifar proses.
Pembahagian & Replikasi Data
Ketika kita belajar di atas bahawa topik dibahagikan kepada partisi, setiap catatan mesej ditiru pada beberapa nod kluster untuk mengekalkan susunan dan data setiap catatan sekiranya salah satu node mati.
Walaupun partisi ditiru pada beberapa nod, masih ada a ketua partition simpul di mana aplikasi membaca dan menulis data mengenai topik tersebut dan pemimpin mereplikasi data pada nod lain, yang disebut sebagai pengikut partisi itu.
Sekiranya data rakaman mesej sangat penting bagi aplikasi, jaminan rekod mesej agar selamat di salah satu nod dapat ditingkatkan dengan meningkatkan faktor replikasi Kluster.
Apa itu Zookeeper?
Zookeeper adalah kedai nilai kunci yang bertoleransi dengan toleransi kesalahan. Apache Kafka sangat bergantung pada Zookeeper untuk menyimpan mekanik kluster seperti degup jantung, menyebarkan kemas kini / konfigurasi, dll).
Ini membolehkan broker Kafka melanggan dirinya sendiri dan mengetahui bila ada perubahan mengenai pemimpin partisi dan pengedaran nod telah berlaku.
Aplikasi pengeluar dan pengguna berkomunikasi secara langsung dengan Zookeeper aplikasi untuk mengetahui node mana yang menjadi pemimpin partisi untuk topik supaya mereka dapat melakukan pembacaan dan penulisan dari ketua partisi.
Penstriman
Pemproses Aliran adalah komponen utama dalam kluster Kafka yang mengambil aliran data rakaman mesej secara berterusan dari topik input, memproses data ini dan membuat aliran data ke topik keluaran yang boleh menjadi apa saja, dari sampah ke Pangkalan Data.
Sangat mungkin untuk melakukan pemprosesan sederhana secara langsung menggunakan API pengeluar / pengguna, walaupun untuk pemprosesan yang kompleks seperti menggabungkan aliran, Kafka menyediakan perpustakaan API Aliran bersepadu tetapi harap maklum bahawa API ini dimaksudkan untuk digunakan dalam pangkalan kode kita sendiri dan tidak ' t menjalankan broker. Ia berfungsi serupa dengan API pengguna dan membantu kami memperluas kerja pemprosesan aliran melalui beberapa aplikasi.
Bila hendak menggunakan Apache Kafka?
Seperti yang telah kita pelajari di bahagian-bahagian di atas, Apache Kafka dapat digunakan untuk menangani sejumlah besar catatan mesej yang dapat termasuk dalam sejumlah topik yang hampir tidak terbatas dalam sistem kami.
Apache Kafka adalah calon yang ideal ketika menggunakan perkhidmatan yang dapat memungkinkan kita mengikuti seni bina berdasarkan acara dalam aplikasi kita. Ini disebabkan oleh kemampuan ketekunan data, toleransi kesalahan dan seni bina yang sangat diedarkan di mana aplikasi kritikal boleh bergantung pada prestasinya.
Senibina Kafka yang berskala dan diedarkan menjadikan penyatuan dengan perkhidmatan mikro sangat mudah dan membolehkan aplikasi menyahpasang dirinya dengan banyak logik perniagaan.
Membuat Topik baru
Kita boleh membuat Topik ujian ujian pada pelayan Apache Kafka dengan arahan berikut:
Buat topik
sudo kafka-topik.sh --create --zookeeper localhost: 2181 --faktor penerapan 1--partition 1 - ujian topik
Inilah yang kita dapat kembali dengan arahan ini: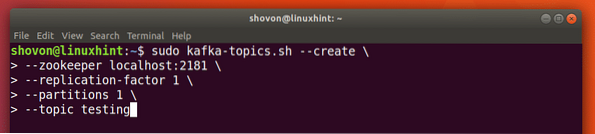
Buat Topik Kafka Baru
Topik ujian akan dibuat yang dapat kami sahkan dengan perintah yang disebutkan:
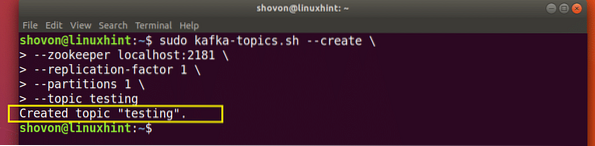
Pengesahan pembuatan Topik Kafka
Menulis Mesej berdasarkan Topik
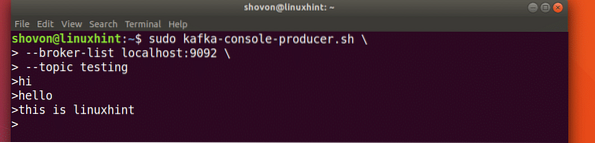
Seperti yang kita pelajari sebelumnya, salah satu API yang ada di Apache Kafka adalah API pengeluar. Kami akan menggunakan API ini untuk membuat mesej baru dan menerbitkan topik yang baru kami buat:
Menulis Mesej kepada Topik
sudo kafka-konsol-pengeluar.sh - localhost senarai broker: 9092 - ujian topikMari lihat output untuk arahan ini:
Terbitkan mesej ke Topik Kafka
Setelah kami menekan kekunci, kami akan melihat tanda anak panah (>) baru yang bermaksud kami dapat memasukkan data sekarang:

Menaip mesej
Cukup masukkan sesuatu dan tekan untuk memulakan baris baru. Saya menaip dalam 3 baris teks:
Membaca Mesej dari Topik
Sekarang setelah kami menerbitkan mesej mengenai Topik Kafka yang kami buat, mesej ini akan berada di sana untuk beberapa waktu yang dapat dikonfigurasi. Kita boleh membacanya sekarang menggunakan API Pengguna:
Membaca Mesej dari Topik
sudo kafka-konsol-pengguna.sh --zookeeper localhost: 2181 --ujian topik - dari awal
Inilah yang kita dapat kembali dengan arahan ini:
Perintah untuk membaca Mesej dari Topik Kafka
Kami akan dapat melihat mesej atau baris yang kami tulis menggunakan API Producer seperti yang ditunjukkan di bawah:
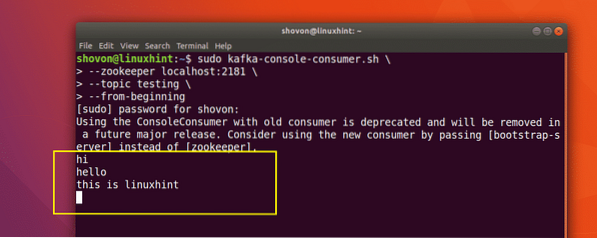
Sekiranya kita menulis satu lagi mesej baru menggunakan Producer API, ia juga akan dipaparkan dengan serta-merta di bahagian Pengguna:
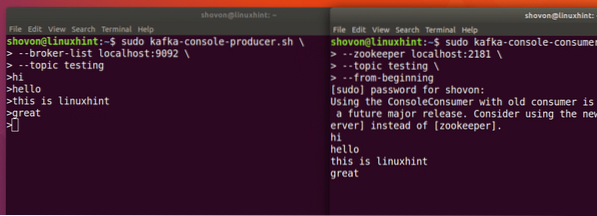
Terbitkan dan Penggunaan pada masa yang sama
Kesimpulannya
Dalam pelajaran ini, kami melihat bagaimana kami mula menggunakan Apache Kafka yang merupakan Broker Mesej yang sangat baik dan dapat bertindak sebagai unit ketekunan data khas juga.


