Gambaran keseluruhan itu sedikit abstrak, jadi mari kita meletakkannya dalam senario dunia nyata, bayangkan anda perlu memantau beberapa pelayan web. Masing-masing menjalankan laman webnya sendiri, dan log baru terus dihasilkan di setiap satu daripadanya setiap saat. Selain itu terdapat sebilangan pelayan e-mel yang perlu anda pantau juga.
Anda mungkin perlu menyimpan data tersebut untuk tujuan penyimpanan rekod dan penagihan, yang merupakan pekerjaan kumpulan yang tidak memerlukan perhatian segera. Anda mungkin ingin menjalankan analisis data untuk membuat keputusan dalam masa nyata yang memerlukan input data yang tepat dan segera. Tiba-tiba anda mendapati diri anda memerlukan penyederhanaan data dengan cara yang masuk akal untuk semua keperluan. Kafka bertindak sebagai lapisan abstraksi yang mana pelbagai sumber dapat menerbitkan aliran data yang berbeza dan yang tertentu pengguna boleh melanggan aliran yang didapati relevan. Kafka akan memastikan bahawa data disusun dengan baik. Ini adalah dalaman Kafka yang perlu kita fahami sebelum kita sampai ke topik Pemisahan dan Kunci.
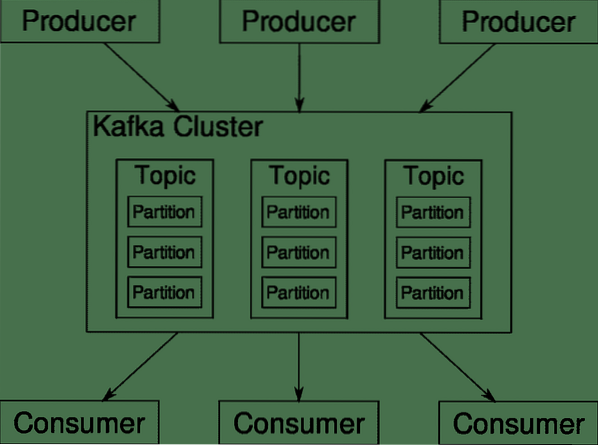
Topik, Broker dan Partisi Kafka
Kafka Topik seperti jadual pangkalan data. Setiap topik terdiri daripada data dari sumber tertentu dari jenis tertentu. Sebagai contoh, kesihatan kluster anda boleh menjadi topik yang terdiri daripada CPU dan maklumat penggunaan memori. Begitu juga, lalu lintas masuk ke seluruh kelompok boleh menjadi topik lain.
Kafka direka untuk diskalakan secara mendatar. Maksudnya, satu contoh Kafka terdiri daripada banyak Kafka broker berjalan di pelbagai nod, masing-masing dapat menangani aliran data selari dengan yang lain. Walaupun sebilangan node gagal, saluran paip data anda dapat terus berfungsi. Topik tertentu kemudian boleh dibahagikan kepada sejumlah partition. Pemisahan ini adalah salah satu faktor penting di sebalik skalabiliti mendatar Kafka.
Pelbagai pengeluar, sumber data untuk topik tertentu, dapat menulis ke topik itu secara serentak kerana masing-masing menulis ke partisi yang berbeza, pada titik tertentu. Sekarang, biasanya data ditugaskan ke partisi secara rawak, kecuali kita memberikannya kunci.
Partition dan Susunan
Sekadar ringkasan, pengeluar menulis data untuk topik tertentu. Topik itu sebenarnya terbahagi kepada beberapa bahagian. Dan setiap partisi hidup secara bebas daripada yang lain, walaupun untuk topik tertentu. Ini boleh menimbulkan banyak kekeliruan ketika pesanan ke data penting. Mungkin anda memerlukan data anda mengikut urutan kronologi tetapi mempunyai banyak partisi untuk aliran data anda tidak menjamin pesanan yang sempurna.
Anda hanya boleh menggunakan satu partisi untuk setiap topik, tetapi itu mengalahkan keseluruhan tujuan seni bina Kafka yang diedarkan. Oleh itu, kita memerlukan penyelesaian lain.
Kunci untuk Pembahagian
Data dari pengeluar dihantar ke partisi secara rawak, seperti yang telah kami sebutkan sebelumnya. Mesej menjadi sebilangan besar data. Apa yang boleh dilakukan pengeluar selain hanya menghantar mesej adalah menambahkan kunci yang sesuai dengannya.
Semua mesej yang disertakan dengan kunci tertentu akan masuk ke partisi yang sama. Jadi, sebagai contoh, aktiviti pengguna dapat dilacak secara kronologi jika data pengguna tersebut ditandai dengan kunci dan sehingga selalu berakhir dalam satu partisi. Mari panggil partition ini p0 dan pengguna u0.
Partition p0 akan selalu mengambil mesej yang berkaitan dengan u0 kerana kunci itu mengikatnya bersama. Tetapi itu tidak bermaksud bahawa p0 hanya terikat dengan itu. Ia juga dapat menerima mesej dari u1 dan u2 jika memiliki kemampuan untuk melakukannya. Begitu juga, partisi lain boleh menggunakan data dari pengguna lain.
Titik bahawa data pengguna tertentu tidak tersebar di partisi yang berbeza memastikan susunan kronologi untuk pengguna tersebut. Walau bagaimanapun, topik keseluruhan mengenai Data pengguna, masih dapat memanfaatkan seni bina diedarkan Apache Kafka.
Kesimpulannya
Walaupun sistem yang diedarkan seperti Kafka menyelesaikan beberapa masalah yang lebih tua seperti kekurangan skalabilitas atau mempunyai satu titik kegagalan. Mereka hadir dengan sekumpulan masalah yang unik untuk reka bentuk mereka sendiri. Mengantisipasi masalah ini adalah tugas penting bagi mana-mana arkitek sistem. Bukan itu sahaja, kadang-kadang anda benar-benar perlu membuat analisis kos-manfaat untuk menentukan sama ada masalah baru itu adalah pertukaran yang baik untuk menyingkirkan yang lebih tua. Pemesanan dan penyegerakan hanyalah puncak gunung es.
Semoga artikel seperti ini dan dokumentasi rasmi dapat membantu anda sepanjang perjalanan.


