Bahagian 1: Menyiapkan satu nod
Hari ini, menyimpan dokumen atau data anda secara elektronik pada peranti storan cepat dan mudah, ia juga murah. Sedang digunakan adalah referensi nama file yang dimaksudkan untuk menjelaskan tentang apa dokumen itu. Sebagai alternatif, data disimpan dalam Sistem Pengurusan Pangkalan Data (DBMS) seperti PostgreSQL, MariaDB, atau MongoDB untuk hanya menamakan beberapa pilihan. Beberapa medium penyimpanan disambungkan secara tempatan atau jarak jauh ke komputer, seperti USB stick, hard disk dalaman atau luaran, Network Attached Storage (NAS), Cloud Storage, atau berasaskan GPU / Flash, seperti pada Nvidia V100 [10].
Sebaliknya, proses sebaliknya, mencari dokumen yang tepat dalam pengumpulan dokumen, agak rumit. Kebanyakannya memerlukan pengesanan format fail tanpa kesalahan, pengindeksan dokumen, dan pengekstrakan konsep utama (klasifikasi dokumen). Di sinilah kerangka Apache Solr masuk. Ia menawarkan antara muka praktikal untuk melakukan langkah-langkah yang disebutkan - membina indeks dokumen, menerima pertanyaan carian, melakukan carian sebenarnya, dan mengembalikan hasil carian. Oleh itu, Apache Solr menjadi teras untuk penyelidikan yang berkesan mengenai pangkalan data atau dokumen silo.
Dalam artikel ini, anda akan belajar bagaimana Apache Solr berfungsi, cara mengatur satu simpul, mengindeks dokumen, melakukan pencarian, dan mendapatkan hasilnya.
Artikel susulan dibuat berdasarkan ini, dan, di dalamnya, kita membincangkan kes penggunaan lain yang lebih spesifik seperti mengintegrasikan PostgreSQL DBMS sebagai sumber data atau load balancing di beberapa nod.
Mengenai projek Apache Solr
Apache Solr adalah kerangka mesin carian berdasarkan pelayan indeks carian Lucene yang kuat [2]. Ditulis di Jawa, ia dikendalikan di bawah payung Apache Software Foundation (ASF) [6]. Ia boleh didapati secara percuma di bawah lesen Apache 2.
Topik "Cari dokumen dan data lagi" memainkan peranan yang sangat penting dalam dunia perisian, dan banyak pembangun menghadapinya secara intensif. Laman web Awesomeopensource [4] menyenaraikan lebih daripada 150 projek sumber terbuka enjin carian. Pada awal 2021, ElasticSearch [8] dan Apache Solr / Lucene adalah dua anjing teratas ketika mencari set data yang lebih besar. Membangunkan enjin carian anda memerlukan banyak pengetahuan, Frank melakukannya dengan perpustakaan AdvaS Advanced Search [3] yang berpusat di Python sejak tahun 2002.
Menyiapkan Apache Solr:
Pemasangan dan pengoperasian Apache Solr tidak rumit, ini hanyalah satu rangkaian langkah yang harus anda laksanakan. Biarkan sekitar 1 jam untuk hasil pertanyaan data pertama. Tambahan pula, Apache Solr bukan hanya projek hobi tetapi juga digunakan dalam persekitaran profesional. Oleh itu, persekitaran sistem operasi yang dipilih direka untuk penggunaan jangka panjang.
Sebagai persekitaran asas untuk artikel ini, kami menggunakan Debian GNU / Linux 11, yang merupakan rilis Debian yang akan datang (pada awal 2021) dan diharapkan akan tersedia pada pertengahan 2021. Untuk tutorial ini, kami menjangkakan anda sudah memasangnya, sama ada sebagai sistem asli, dalam mesin maya seperti VirtualBox, atau bekas AWS.
Selain komponen asas, anda memerlukan pakej perisian berikut untuk dipasang pada sistem:
- Keriting
- Lalai-java
- Libcommons-cli-java
- Libxerces2-java
- Libtika-java (perpustakaan dari projek Apache Tika [11])
Pakej ini adalah komponen standard Debian GNU / Linux. Sekiranya belum dipasang, anda boleh memasangnya secara langsung sebagai pengguna dengan hak pentadbiran, misalnya, root atau melalui sudo, ditunjukkan seperti berikut:
# apt-get install curl default-java libcommons-cli-java libxerces2-java libtika-javaSetelah menyiapkan persekitaran, langkah ke-2 adalah pemasangan Apache Solr. Setakat ini, Apache Solr tidak tersedia sebagai pakej Debian biasa. Oleh itu, diperlukan untuk mendapatkan semula Apache Solr 8.8 dari bahagian muat turun laman web projek [9] terlebih dahulu. Gunakan perintah wget di bawah untuk menyimpannya di direktori / tmp sistem anda:
$ wget -O / tmp https: // muat turun.apache.org / lucene / solr / 8.8.0 / solr-8.8.0.tgzSuis -O memendekkan -keluaran-dokumen dan membuat wget menyimpan tar yang diambil.fail gz di direktori yang diberikan. Arkib berukuran kira-kira 190M. Seterusnya, bongkar arkib ke dalam direktori / opt menggunakan tar. Hasilnya, anda akan menemui dua subdirektori - / opt / solr dan / opt / solr-8.8.0, sedangkan / opt / solr ditetapkan sebagai pautan simbolik ke yang terakhir. Apache Solr dilengkapi dengan skrip persediaan yang anda laksanakan seterusnya, seperti berikut:
# / opt / solr-8.8.0 / bin / install_solr_service.shIni menghasilkan penciptaan solr pengguna Linux dalam perkhidmatan Solr ditambah dengan direktori rumahnya di bawah / var / solr mewujudkan perkhidmatan Solr, ditambah dengan node yang sesuai, dan memulakan perkhidmatan Solr di port 8983. Ini adalah nilai lalai. Sekiranya anda tidak berpuas hati dengan mereka, anda boleh mengubahnya semasa pemasangan atau bahkan lambat kerana skrip pemasangan menerima suis yang sesuai untuk penyesuaian persediaan. Kami mengesyorkan anda melihat dokumentasi Apache Solr mengenai parameter ini.
Perisian Solr disusun dalam direktori berikut:
- tong sampah
mengandungi binari dan fail Solr untuk menjalankan Solr sebagai perkhidmatan - contrib
perpustakaan Solr luaran seperti pengendali import data dan perpustakaan Lucene - jarak
perpustakaan Solr dalaman - dokumen
pautan ke dokumentasi Solr yang terdapat dalam talian - contoh
contoh set data atau beberapa kes / senario penggunaan - lesen
lesen perisian untuk pelbagai komponen Solr - pelayan
fail konfigurasi pelayan, seperti pelayan / dll untuk perkhidmatan dan port
Dengan lebih terperinci, anda boleh membaca mengenai direktori ini dalam dokumentasi Apache Solr [12].
Menguruskan Apache Solr:
Apache Solr berfungsi sebagai perkhidmatan di latar belakang. Anda boleh memulakannya dengan dua cara, sama ada menggunakan systemctl (baris pertama) sebagai pengguna dengan izin pentadbiran atau langsung dari direktori Solr (baris kedua). Kami menyenaraikan kedua-dua arahan terminal di bawah:
# systemctl mulakan solr$ solr / bin / solr permulaan
Menghentikan Apache Solr dilakukan dengan cara yang sama:
# systemctl berhenti solr$ solr / bin / solr berhenti
Cara yang sama berlaku dalam memulakan semula perkhidmatan Apache Solr:
# systemctl mulakan semula solr$ solr / bin / solr mulakan semula
Selanjutnya, status proses Apache Solr dapat ditunjukkan seperti berikut:
# sistemctl status solrstatus $ solr / bin / solr
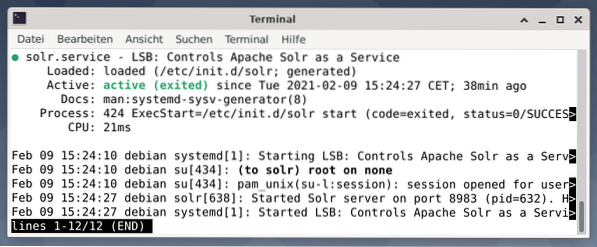
Output menyenaraikan fail perkhidmatan yang dimulakan, kedua-dua cap waktu dan mesej log yang sesuai. Gambar di bawah menunjukkan bahawa perkhidmatan Apache Solr dimulakan di port 8983 dengan proses 632. Proses berjaya dijalankan selama 38 minit.
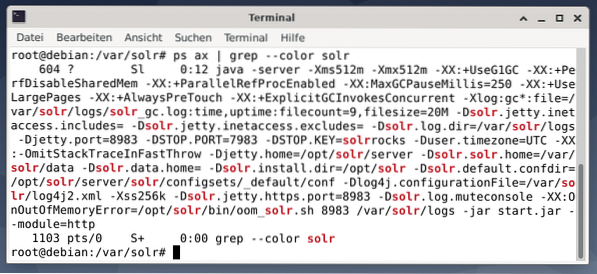
Untuk mengetahui apakah proses Apache Solr aktif, anda juga boleh memeriksa silang menggunakan perintah ps dalam kombinasi dengan grep. Ini menghadkan output ps ke semua proses Apache Solr yang sedang aktif.
# ps kapak | grep - warna solrGambar di bawah menunjukkan ini untuk satu proses. Anda melihat panggilan Java yang disertai dengan senarai parameter, misalnya port penggunaan memori (512M) untuk mendengarkan pada 8983 untuk pertanyaan, 7983 untuk permintaan berhenti, dan jenis sambungan (http).
Menambah pengguna:
Proses Apache Solr dijalankan dengan pengguna tertentu bernama solr. Pengguna ini sangat membantu dalam menguruskan proses Solr, memuat naik data, dan mengirim permintaan. Setelah disiapkan, pengguna solr tidak mempunyai kata laluan dan diharapkan mempunyai satu untuk log masuk untuk melangkah lebih jauh. Tetapkan kata laluan untuk pengguna seperti root pengguna, ia ditunjukkan seperti berikut:
# passwd solrPentadbiran Solr:
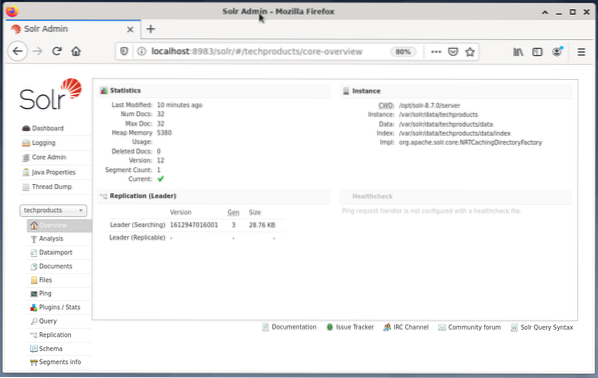
Menguruskan Apache Solr dilakukan dengan menggunakan Solr Dashboard. Ini boleh diakses melalui penyemak imbas web dari http: // localhost: 8983 / solr. Gambar di bawah menunjukkan pandangan utama.
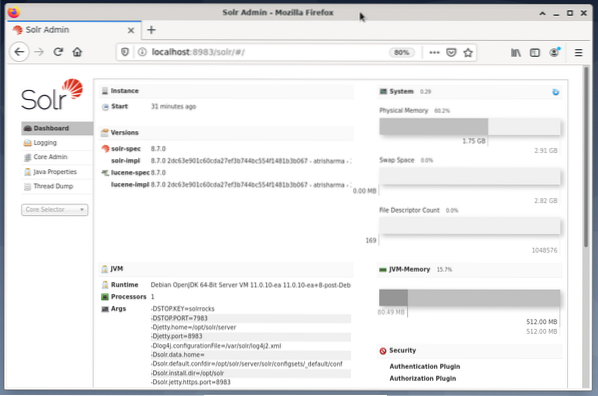
Di sebelah kiri, anda melihat menu utama yang membawa anda ke bahagian untuk pembalakan, pentadbiran teras Solr, penyediaan Java, dan maklumat status. Pilih inti yang dikehendaki menggunakan kotak pilihan di bawah menu. Di sebelah kanan menu, maklumat yang sesuai dipaparkan. Entri menu Dashboard menunjukkan perincian lebih lanjut mengenai proses Apache Solr, serta penggunaan memori dan pemuatan semasa.
Harap maklum bahawa kandungan Dashboard berubah bergantung pada bilangan teras Solr, dan dokumen yang telah diindeks. Perubahan mempengaruhi kedua item menu dan maklumat yang sesuai yang dapat dilihat di sebelah kanan.
Memahami Bagaimana Mesin Pencari Berfungsi:
Secara ringkas, mesin pencari menganalisis dokumen, mengkategorikannya, dan membolehkan anda melakukan carian berdasarkan kategorinya. Pada dasarnya, proses ini terdiri daripada tiga tahap, yang diistilahkan sebagai merangkak, mengindeks, dan peringkat [13].
Merangkak adalah peringkat pertama dan menerangkan proses di mana kandungan baru dan kemas kini dikumpulkan. Mesin pencari menggunakan robot yang juga dikenal sebagai labah-labah atau perayap, oleh itu istilah merangkak untuk melalui dokumen yang tersedia.
Tahap kedua disebut pengindeksan. Kandungan yang dikumpulkan sebelum ini dapat dicari dengan mengubah dokumen asalnya menjadi format yang difahami oleh mesin pencari. Kata kunci dan konsep diekstrak dan disimpan dalam pangkalan data (besar-besaran).
Tahap ketiga disebut peringkat dan menerangkan proses menyusun hasil carian mengikut kesesuaiannya dengan pertanyaan carian. Adalah umum untuk menampilkan hasil dalam urutan menurun sehingga hasil yang paling relevan dengan pertanyaan pencari adalah yang pertama.
Apache Solr berfungsi sama dengan proses tiga peringkat yang dijelaskan sebelumnya. Seperti mesin carian Google yang popular, Apache Solr menggunakan urutan mengumpulkan, menyimpan, dan mengindeks dokumen dari sumber yang berbeza dan menjadikannya tersedia / dicari dalam masa nyata.
Apache Solr menggunakan pelbagai cara untuk mengindeks dokumen termasuk yang berikut [14]:
- Menggunakan Pengendali Permintaan Indeks semasa memuat naik dokumen terus ke Solr. Dokumen-dokumen ini harus dalam format JSON, XML / XSLT, atau CSV.
- Menggunakan Pengendali Permintaan Pengekstrakan (Sel Solr). Dokumen harus dalam format PDF atau Office, yang disokong oleh Apache Tika.
- Menggunakan Pengendali Import Data, yang menyampaikan data dari pangkalan data dan mengkatalognya menggunakan nama lajur. Pengendali Import Data mengambil data dari e-mel, umpan RSS, data XML, pangkalan data, dan fail teks biasa sebagai sumber.
Penangan pertanyaan digunakan dalam Apache Solr ketika permintaan carian dihantar. Pengendali pertanyaan menganalisis pertanyaan yang diberikan berdasarkan konsep pengendali indeks yang sama untuk memadankan pertanyaan dan dokumen yang diindeks sebelumnya. Perlawanan diberi peringkat mengikut kesesuaian atau kesesuaiannya. Contoh ringkas pertanyaan ditunjukkan di bawah.
Memuat naik Dokumen:
Demi kesederhanaan, kami menggunakan contoh dataset untuk contoh berikut yang sudah disediakan oleh Apache Solr. Memuat naik dokumen dilakukan sebagai pengguna solr. Langkah 1 adalah penciptaan inti dengan nama produk produk (untuk sebilangan item teknologi).
$ solr / bin / solr create -c techproducts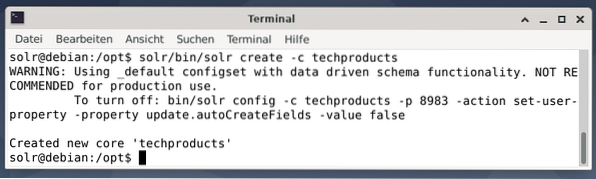
Semuanya baik-baik saja jika anda melihat mesej "Menciptakan 'produk teknikal' teras baru". Langkah 2 adalah menambahkan data (data XML dari exampledocs) ke produk teknologi teras yang dibuat sebelumnya. Sedang digunakan adalah postingan alat yang di parameter oleh -c (nama inti) dan dokumen yang akan dimuat.
$ solr / bin / post -c techproducts solr / example / exampledocs / *.xmlIni akan menghasilkan output yang ditunjukkan di bawah dan akan mengandungi keseluruhan panggilan serta 14 dokumen yang telah diindeks.
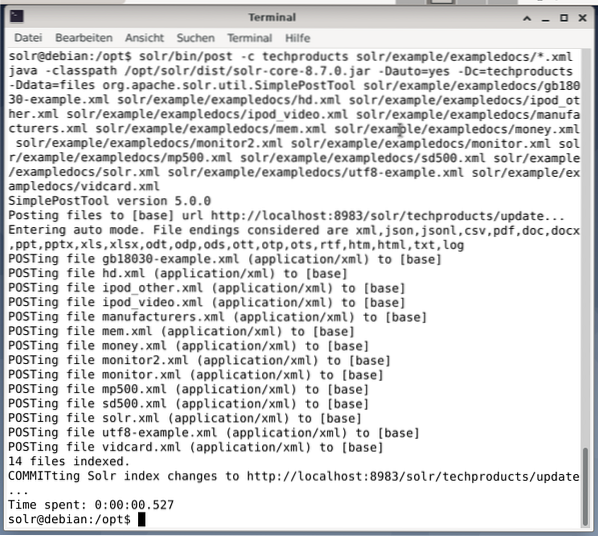
Juga, Papan Pemuka menunjukkan perubahan. Entri baru bernama techproducts dapat dilihat di menu dropdown di sebelah kiri, dan jumlah dokumen yang sesuai berubah di sebelah kanan. Malangnya, pandangan terperinci mengenai set data mentah tidak mungkin.
Sekiranya inti / koleksi perlu dikeluarkan, gunakan arahan berikut:
$ solr / bin / solr delete -c techproductsData Pertanyaan:
Apache Solr menawarkan dua antara muka untuk membuat pertanyaan data: melalui Papan Pemuka dan baris arahan berasaskan web. Kami akan menerangkan kedua-dua kaedah di bawah.
Menghantar pertanyaan melalui papan pemuka Solr dilakukan seperti berikut:
- Pilih produk teknologi node dari menu lungsur.
- Pilih entri Pertanyaan dari menu di bawah menu lungsur.
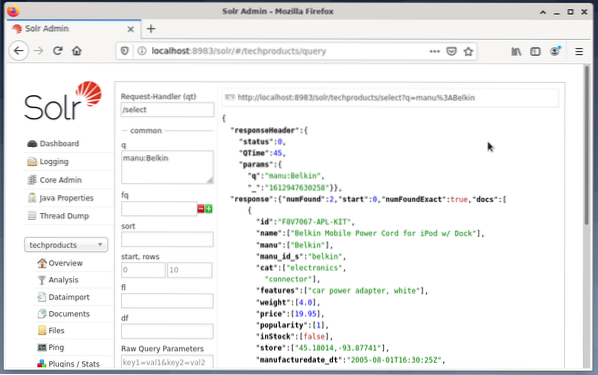
Medan entri muncul di sebelah kanan untuk merumuskan pertanyaan seperti penangan permintaan (qt), pertanyaan (q), dan urutan urutan (urutkan). - Pilih bidang entri Pertanyaan, dan ubah isi entri dari "*: *" menjadi "manu: Belkin". Ini membatasi pencarian dari "semua bidang dengan semua entri" ke "set data yang memiliki nama Belkin di bidang manu". Dalam kes ini, nama manu menyingkat pengeluar dalam set data contoh.
- Seterusnya, tekan butang dengan Execute Query. Hasilnya adalah permintaan HTTP yang dicetak di atas, dan hasil pertanyaan carian dalam format data JSON di bawah.
Baris arahan menerima pertanyaan yang sama seperti di Dashboard. Perbezaannya ialah anda mesti mengetahui nama bidang pertanyaan. Untuk menghantar pertanyaan yang sama seperti di atas, anda harus menjalankan perintah berikut di terminal:
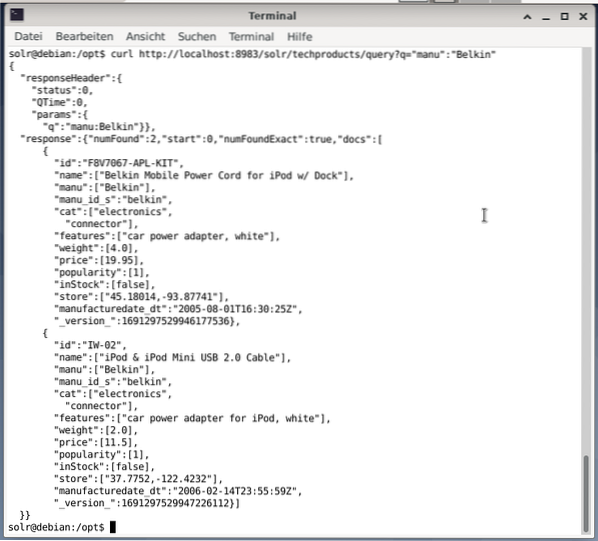
$ ikalhttp: // localhost: 8983 / solr / techproducts / pertanyaan?q = "manu": "Belkin
Keluarannya dalam format JSON, seperti ditunjukkan di bawah. Hasilnya terdiri daripada tajuk respons dan tindak balas sebenar. Respons terdiri daripada dua set data.
Mengakhiri:
Selamat bertunang! Anda telah mencapai tahap pertama dengan kejayaan. Infrastruktur asas telah disediakan, dan anda telah belajar bagaimana memuat naik dan menyoal dokumen.
Langkah seterusnya akan merangkumi cara menyempurnakan pertanyaan, merumuskan pertanyaan yang lebih kompleks, dan memahami pelbagai bentuk web yang disediakan oleh halaman pertanyaan Apache Solr. Juga, kita akan membincangkan cara memproses hasil carian menggunakan format output yang berbeza seperti XML, CSV, dan JSON.
Mengenai pengarang:
Jacqui Kabeta adalah pakar persekitaran, penyelidik, pelatih, dan mentor yang gemar. Di beberapa negara Afrika, dia telah bekerja di industri IT dan persekitaran NGO.
Frank Hofmann adalah pemaju IT, pelatih, dan pengarang dan lebih suka bekerja dari Berlin, Geneva, dan Cape Town. Pengarang bersama Buku Pengurusan Pakej Debian tersedia dari dpmb.org
- [1] Apache Solr, https: // lucene.apache.org / solr /
- [2] Perpustakaan Cari Lucene, https: // lucene.apache.org /
- [3] Carian Lanjutan AdvaS, https: // pypi.org / projek / AdvaS-Advanced-Search /
- [4] 165 Projek Sumber Terbuka Enjin Carian Teratas, https: // awesomeopensource.com / projek / enjin carian
- [5] Carian Elastik, https: // www.elastik.co / de / elastik carian /
- [6] Apache Software Foundation (ASF), https: // www.apache.org /
- [7] FESS, https: // fess.codelib.org / indeks.html
- [8] Pencarian Elastik, https: // www.elastik.kod/
- [9] Apache Solr, bahagian Muat turun, https: // lucene.apache.org / solr / muat turun.htm
- [10] Nvidia V100, https: // www.nvidia.com / en-us / pusat data / v100 /
- [11] Apache Tika, https: // tika.apache.org /
- [12] Susun atur direktori Apache Solr, https: // lucene.apache.org / solr / panduan / 8_8 / memasang-solr.html # susun atur direktori
- [13] Cara Mesin Pencari Berfungsi: Merangkak, Mengindeks, dan Peringkat. Panduan pemula untuk SEO https: // moz.com / beginners-guide-to-seo / bagaimana-search-engine-beroperasi
- [14] Mulakan dengan Apache Solr, https: // sematext.com / guide / solr / #: ~: text = Solr% 20works% 20by% 20gathering% 2C% 20store, with% 20huge% 20volume% 20of% 20data


