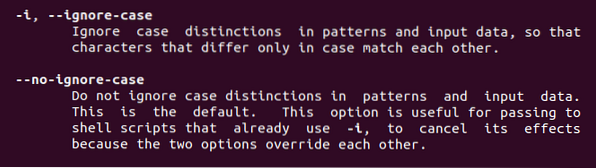
Dari arahan itu, kita akan menemui dua ciri yang dinyatakan di atas. -Maksud saya untuk mengabaikan kes itu, di mana sahaja kata kunci ini digunakan, kasih sayang kes dihapuskan.
Prasyarat
Untuk memenuhi pencapaian fungsi tersebut dalam sistem operasi Linux, kita perlu memasang OS Linux. Selepas konfigurasi, anda akan memberikan maklumat pengguna yang diperlukan, dengan bantuan pengguna akan log masuk. Selanjutnya, apabila nama pengguna dan kata laluan diberikan, pengguna akan dapat mengakses semua ciri sistem operasi terbina dalam. Akhirnya, setelah desktop diakses, anda diminta untuk mengakses terminal, kerana perintah harus dijalankan di atasnya.
Contoh 1:
Dalam contoh ini, kita akan melihat bagaimana grep membantu dalam memanfaatkan kepekaan kes. Pertimbangkan fail bernama file11.txt. Fail mengandungi data berikut di dalamnya; seperti yang anda lihat perkataan mangga ditulis dengan cara yang berbeza, beberapa perkataan dalam huruf besar dan beberapa huruf kecil. Dengan menggunakan perintah kucing kita akan memaparkan data fail.
$ fail kucing11.txt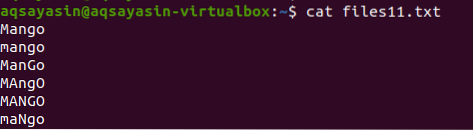
Setelah perintah digunakan untuk menampilkan data, dapat dilihat bahwa satu-satunya kata yang sesuai dengan huruf besar yang terdapat dalam perintah akan ditampilkan. Semua huruf dalam huruf kecil.
$ grep mango files11.txt
Sekarang untuk memahami konsep kepekaan huruf besar, kita akan menggunakan "-I" dalam perintah untuk menangani kepekaan huruf besar dengan memberikan semua data yang ada dalam file, padanan dengan string yang ada di dalam perintah.
$ grep -I fail mangga11.txt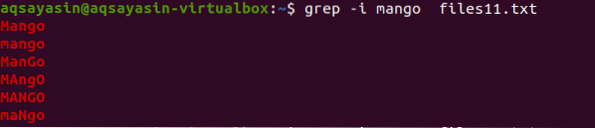
Dari hasilnya, Anda akan mengetahui bahawa semua data yang sesuai dengan kata "mangga" ditampilkan baik dengan beberapa kata ditulis dengan huruf besar dan ada yang huruf kecil.
Contoh 2
Contoh ini menyerupai yang pertama, perbezaannya ialah hanya satu perkataan yang diperoleh. Perintah ini membantu mendapatkan keseluruhan rentetan dengan memadankannya dengan kata yang disediakan dalam perintah. Mari kita mempunyai fail filea.txt. sebagai contoh, kami ingin mengambil rekod mengikut pertandingan yang diberikan.
$ kucing filea.txt
Sekarang gunakan perintah yang sama untuk mengabaikan kes dan menggambarkan outputnya. Kata teknikal dipaparkan dengan tidak memasukkan huruf besar untuk menjadikannya peka huruf besar kecil.

Contoh 3
Kaedah lain menggunakan grep untuk mengabaikan huruf besar adalah dengan memperkenalkan nama fail terlebih dahulu dan kemudian menerapkan perintah -I dengan grep berikut "|" pengendali. Kucing digunakan bersamaan dengan "|". Mari kita mempunyai fail bernama file24.txt. sebagai contoh.
$ Cat fail24.txt | grep -Saya "Aqsa"Perintah ini akan mengambil perkataan "Aqsa" dalam kedua-dua huruf besar dan kecil.

Contoh 4
Melangkah ke arah contoh lain. Di sini kita akan memaparkan data fail yang mengandung kata "my". Di sini pencarian dilakukan dengan memperkenalkan direktori sehingga perintah akan menyusun kata dalam semua fail yang mempunyai ekstensi .txt dalam sistem.
$ grep -Saya / rumah / aqsayasin / *.txt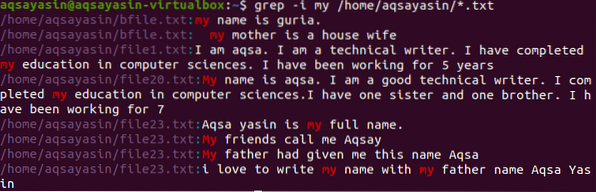
Gambar di atas menunjukkan output yang diperoleh dari arahan. Perkataan "saya" disorot, yaitu dalam kedua kes tersebut. Beberapa fail menyimpannya dalam huruf kecil sementara yang lain memilikinya dalam huruf besar. Alamat fail dan nama fail juga dipaparkan.
Contoh 5
Contoh ini dapat diterapkan ke direktori yang memiliki semua file di dalamnya. Batasan akan diterapkan untuk menampilkan hasil spesifik yang dipadankan dengan kata yang telah kami tetapkan dalam perintah. Kata "is" digunakan untuk mencari di semua file yang ada dalam sistem.
$ grep -Saya / rumah / aqsayasin / fail *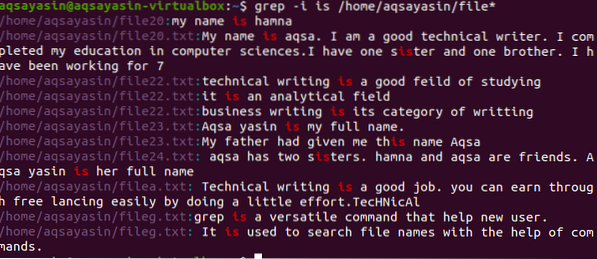
Output menunjukkan keseluruhan rentetan yang mengandungi perkataan yang sesuai di dalamnya. Seperti "is" ditulis secara berasingan atau digabungkan dalam kata lain i.e. saudari.
Contoh 6
Perintah seterusnya menunjukkan bagaimana -iw bekerjasama dalam arahan. Selain di sini, pencarian dilakukan melalui dua perkataan dalam satu fail. Tanda belakang dan "|" digunakan untuk menerangkan dua perkataan dalam fail sementara -w digunakan untuk padanan tepat kata masing-masing dalam fail.
$ grep -iw 'hamna \ | rumah' fail21.txt$ grep 'hamn \ | rumah' fail21.txt

-Saya akan mengabaikan kepekaan kes. Dalam contoh di atas, kita dapat melihat bahawa kehadiran -w dengan -I, membolehkan sebuah rumah pada perintah pertama tidak dipertimbangkan kerana -w membenarkan padanan yang tepat. Pada perintah kedua, kami telah membuang kedua -iw, oleh itu kedua-dua perkataan itu dipaparkan setelah dipadankan dalam rentetan.
Contoh 7
Lebih daripada satu perkataan dicari dengan menggunakan kaedah yang berbeza. Kedua-dua perkataan dicari dari file yang sama kata-kata ini adalah "job" dan "earn". Perolehan diambil dari pembelajaran kata dan perhatikan bahawa setiap perkataan dipisahkan dari kata kunci -e.
$ grep -I -saya -mendapatkan filea.txt
Gambar di atas menunjukkan keseluruhan rentetan dalam perenggan mengenai kata-kata yang terdapat dalam perintah. Seperti contoh di atas, -Saya telah mengabaikan semua diskriminasi kes dengan kata kerja dan dapatkan.
Contoh 8
Dalam contoh ini, mencari dua perkataan yang terdapat dalam semua fail .sambungan txt. Kedua perkataan ini dipisahkan dengan -e, kerana -e adalah cara yang tepat untuk pemisahan dua perkataan. Output yang diperoleh akan mempunyai kedua-dua perkataan yang ditunjukkan dalam semua fail sambungan teks. Keseluruhan alamat fail diperoleh dan dipaparkan. -Saya akan mengabaikan kepekaan kes dan akan memaparkan kedua-dua perkataan yang terdapat dalam semua fail.
$ grep -I -e job -e earn / home / aqsayasin / *.txt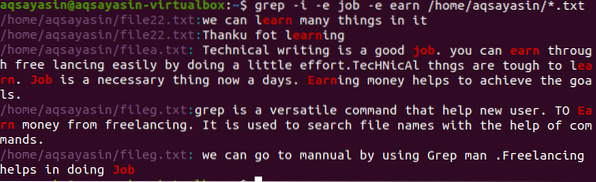
Kesimpulannya
Dalam panduan ini, kami telah menggunakan contoh paling mudah untuk menghuraikan konsep kepekaan kes. Kami telah berusaha sedaya upaya untuk melalui setiap aspek untuk meningkatkan pengetahuan mengenai grep.


