Artikel ini menunjukkan kepada anda cara mencari pendua dalam data dan membuang pendua menggunakan fungsi Pandas Python.
Dalam artikel ini, kami telah mengambil kumpulan data populasi dari berbagai negeri di Amerika Syarikat, yang tersedia di a .format fail csv. Kami akan membaca .fail csv untuk menunjukkan kandungan asal fail ini, seperti berikut:
import panda sebagai pddf_state = pd.read_csv ("C: / Pengguna / DELL / Desktop / populasi_ds.csv ")
cetak (df_state)
Dalam tangkapan skrin berikut, anda dapat melihat kandungan pendua fail ini:
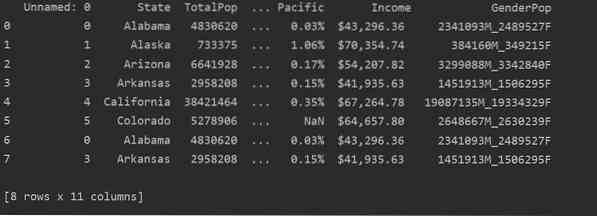
Mengenal pasti Pendua di Pandas Python
Anda perlu menentukan sama ada data yang anda gunakan mempunyai baris pendua. Untuk memeriksa penduaan data, anda boleh menggunakan salah satu kaedah yang dibahas di bahagian berikut.
Kaedah 1:
Baca fail csv dan masukkan ke dalam kerangka data. Kemudian, kenal pasti baris pendua menggunakan didua () fungsi. Akhirnya, gunakan pernyataan cetak untuk memaparkan baris pendua.
import panda sebagai pddf_state = pd.read_csv ("C: / Pengguna / DELL / Desktop / populasi_ds.csv ")
Dup_Rows = df_state [df_state.digandakan ()]
cetak ("\ n \ nDuplikasi Baris: \ n ".format (Dup_Rows))
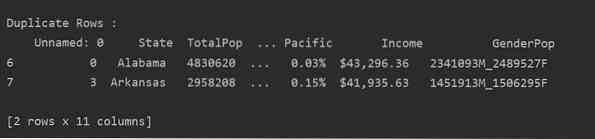
Kaedah 2:
Dengan menggunakan kaedah ini, digandakan lajur akan ditambahkan ke hujung jadual dan ditandakan sebagai 'Benar' sekiranya baris digandakan.
import panda sebagai pddf_state = pd.read_csv ("C: / Pengguna / DELL / Desktop / populasi_ds.csv ")
df_state ["is_duplicate"] = df_state.didua ()
cetak ("\ n ".format (df_state))
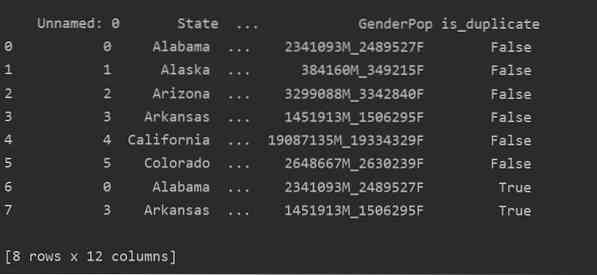
Menjatuhkan Pendua di Pandas Python
Baris pendua dapat dikeluarkan dari kerangka data anda menggunakan sintaks berikut:
drop_duplicates (subset = ", keep =", inplace = False)
Tiga parameter di atas adalah pilihan dan dijelaskan dengan lebih terperinci di bawah:
simpan: parameter ini mempunyai tiga nilai yang berbeza: Pertama, Terakhir dan Salah. Nilai Pertama menyimpan kejadian pertama dan membuang pendua berikutnya, Nilai terakhir menyimpan hanya kejadian terakhir dan membuang semua pendua sebelumnya, dan Nilai Salah membuang semua baris pendua.
subset: label yang digunakan untuk mengenal pasti baris pendua
di tempat: mengandungi dua syarat: Betul dan Salah. Parameter ini akan menghilangkan baris pendua jika disetel ke True.
Buang Pendua Hanya Mengekalkan Kejadian Pertama
Apabila anda menggunakan "keep = first", hanya kejadian baris pertama yang akan disimpan, dan semua pendua yang lain akan dikeluarkan.
Contohnya
Dalam contoh ini, hanya baris pertama yang akan disimpan, dan baki pendua yang akan dihapuskan:
import panda sebagai pddf_state = pd.read_csv ("C: / Pengguna / DELL / Desktop / populasi_ds.csv ")
Dup_Rows = df_state [df_state.digandakan ()]
cetak ("\ n \ nDuplikasi Baris: \ n ".format (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (simpan = 'pertama')
cetak ('\ n \ nResult DataFrame setelah penghapusan pendua: \ n', DF_RM_DUP.kepala (n = 5))
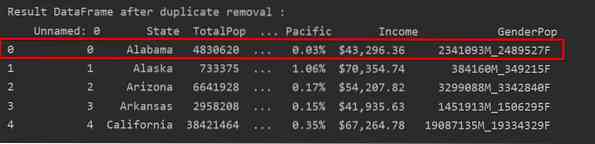
Pada tangkapan skrin berikut, kejadian baris pertama yang dikekalkan diserlahkan dengan warna merah dan pendua yang tersisa dikeluarkan:
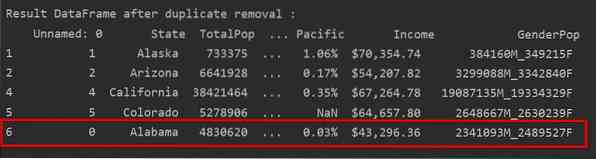
Buang Pendua Yang Menyimpan Hanya Kejadian Terakhir
Apabila anda menggunakan "keep = last", semua baris pendua kecuali kejadian terakhir akan dikeluarkan.
Contohnya
Dalam contoh berikut, semua baris pendua dikeluarkan kecuali hanya kejadian terakhir.
import panda sebagai pddf_state = pd.read_csv ("C: / Pengguna / DELL / Desktop / populasi_ds.csv ")
Dup_Rows = df_state [df_state.digandakan ()]
cetak ("\ n \ nDuplikasi Baris: \ n ".format (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (simpan = 'terakhir')
cetak ('\ n \ nResult DataFrame setelah penghapusan pendua: \ n', DF_RM_DUP.kepala (n = 5))
Dalam gambar berikut, pendua dikeluarkan dan hanya kejadian baris terakhir yang disimpan:
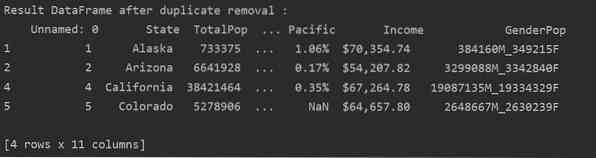
Buang Semua Baris Pendua
Untuk membuang semua baris pendua dari jadual, tetapkan “keep = False,” seperti berikut:
import panda sebagai pddf_state = pd.read_csv ("C: / Pengguna / DELL / Desktop / populasi_ds.csv ")
Dup_Rows = df_state [df_state.digandakan ()]
cetak ("\ n \ nDuplikasi Baris: \ n ".format (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (simpan = Salah)
cetak ('\ n \ nResult DataFrame setelah penghapusan pendua: \ n', DF_RM_DUP.kepala (n = 5))
Seperti yang anda lihat pada gambar berikut, semua pendua dikeluarkan dari kerangka data:
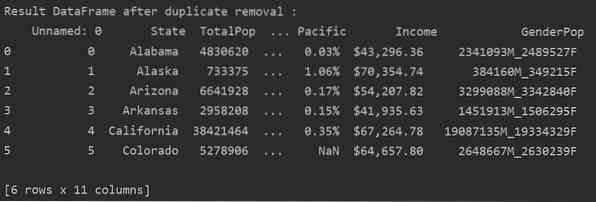
Buang Pendua Berkaitan dari Lajur yang Ditentukan
Secara lalai, fungsi memeriksa semua baris pendua dari semua lajur dalam bingkai data yang diberikan. Tetapi, anda juga boleh menentukan nama lajur dengan menggunakan parameter subset.
Contohnya
Dalam contoh berikut, semua pendua yang berkaitan dikeluarkan dari lajur 'Negeri'.
import panda sebagai pddf_state = pd.read_csv ("C: / Pengguna / DELL / Desktop / populasi_ds.csv ")
Dup_Rows = df_state [df_state.digandakan ()]
cetak ("\ n \ nDuplikasi Baris: \ n ".format (Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates (subset = 'Negeri')
cetak ('\ n \ nResult DataFrame setelah penghapusan pendua: \ n', DF_RM_DUP.kepala (n = 6))
Kesimpulannya
Artikel ini menunjukkan kepada anda cara menghapus baris pendua dari kerangka data menggunakan drop_duplikat () berfungsi di Pandas Python. Anda juga dapat menghapus data pendua atau kelebihan menggunakan fungsi ini. Artikel itu juga menunjukkan kepada anda cara mengenal pasti pendua dalam kerangka data anda.


