Dalam artikel ini, kita akan membahas penggunaan asas kumpulan mengikut fungsi dalam ular sawa panda. Semua arahan dilaksanakan pada editor Pycharm.
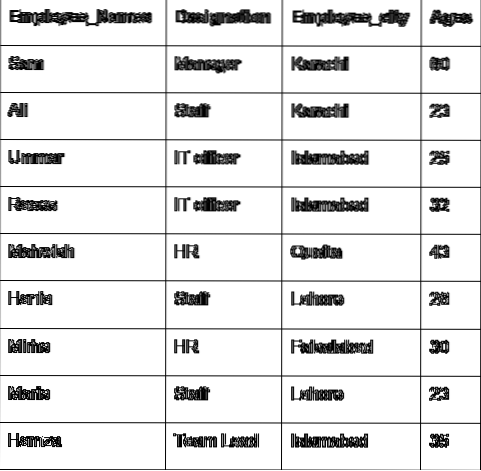
Mari kita bincangkan konsep utama kumpulan dengan bantuan data pekerja. Kami telah membuat kerangka data dengan beberapa perincian pekerja yang berguna (Nama_ Pekerja, Jawatan, Kakitangan_Peringkat, Umur).
Gabungan Rentetan menggunakan Kumpulan mengikut Fungsi
Dengan menggunakan fungsi kumpulan, anda boleh menggabungkan rentetan. Rekod yang sama dapat digabungkan dengan ',' dalam satu sel.
Contohnya
Dalam contoh berikut, kami telah menyusun data berdasarkan lajur 'Penunjukan' pekerja dan bergabung dengan Karyawan yang mempunyai sebutan yang sama. Fungsi lambda diterapkan pada 'Employees_Name'.
import panda sebagai pddf = pd.DataFrame (
'Nama Pegawai': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Jawatan': ['Pengurus', 'Kakitangan', 'pegawai IT', 'pegawai IT', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.kumpulan ("Jawatan") ['Nama Pekerja'].memohon (lambda Employee_Names: ','.sertai (Nama_ Pekerja))
cetak (df1)
Apabila kod di atas dijalankan, output berikut akan dipaparkan:
Menyusun Nilai mengikut tertib menaik
Gunakan objek kumpulan ke dalam bingkai data biasa dengan memanggil '.to_frame () 'dan kemudian gunakan reset_index () untuk reindexing. Isih nilai lajur dengan memanggil sort_values ().
Contohnya
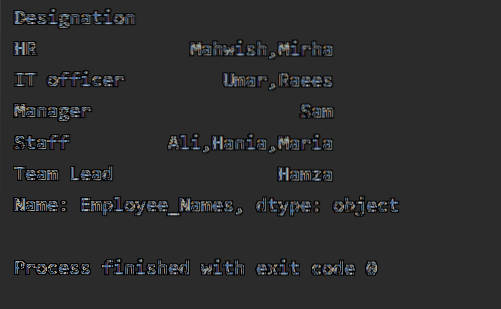
Dalam contoh ini, kita akan menyusun umur Pekerja mengikut urutan menaik. Dengan menggunakan kod berikut, kami telah mengambil 'Employee_Age' dalam urutan menaik dengan 'Employee_Names'.
import panda sebagai pddf = pd.DataFrame (
'Nama Pekerja': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Jawatan': ['Pengurus', 'Kakitangan', 'pegawai IT', 'pegawai IT', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.kumpulan oleh ('Employee_Names') ['Employee_Age'].jumlah ().ke_frame ().tetapkan semula_index ().sort_values (oleh = 'Employee_Age')
cetak (df1)
Penggunaan agregat dengan kumpulan
Terdapat sejumlah fungsi atau gabungan yang dapat anda terapkan pada kumpulan data seperti kiraan (), jumlah (), rata-rata (), median (), mod (), std (), min (), max ().
Contohnya
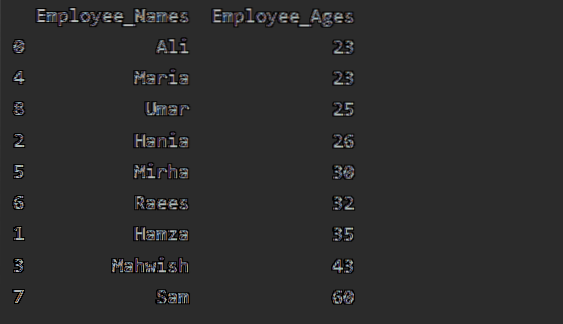
Dalam contoh ini, kami telah menggunakan fungsi 'count ()' dengan groupby untuk menghitung Pekerja yang tergolong dalam 'Employee_city' yang sama.
import panda sebagai pddf = pd.DataFrame (
'Nama Pekerja': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Jawatan': ['Pengurus', 'Kakitangan', 'pegawai IT', 'pegawai IT', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.kumpulan ('Employee_city').kira ()
cetak (df1)
Seperti yang anda dapat melihat output berikut, di bawah lajur Penunjukan, Nama Karyawan, dan Karyawan_Age, hitung nombor yang dimiliki oleh bandar yang sama:
Visualisasikan data menggunakan kumpulan
Dengan menggunakan 'import matplotlib.pyplot ', anda dapat memvisualisasikan data anda ke dalam grafik.
Contohnya
Di sini, contoh berikut menggambarkan 'Employee_Age' dengan 'Employee_Nmaes' dari DataFrame yang diberikan dengan menggunakan penyataan kumpulan.
import panda sebagai pdimport matplotlib.pyplot sebagai plt
kerangka data = pd.DataFrame (
'Nama Pekerja': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Jawatan': ['Pengurus', 'Kakitangan', 'pegawai IT', 'pegawai IT', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.klf ()
kerangka data.kumpulan ('Nama_ Pekerja').jumlah ().plot (jenis = 'bar')
plt.tunjuk ()
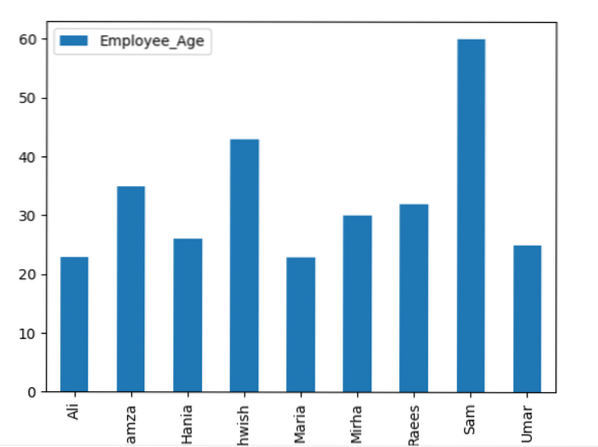
Contohnya
Untuk memplot grafik bertumpuk menggunakan groupby, putar 'stacked = true' dan gunakan kod berikut:
import panda sebagai pdimport matplotlib.pyplot sebagai plt
df = pd.DataFrame (
'Nama Pekerja': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Jawatan': ['Pengurus', 'Kakitangan', 'pegawai IT', 'pegawai IT', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df.kumpulan oleh (['Employee_city', 'Employee_Names']).saiz ().lepaskan ().plot (jenis = 'bar', ditumpuk = Benar, ukuran huruf = '6')
plt.tunjuk ()
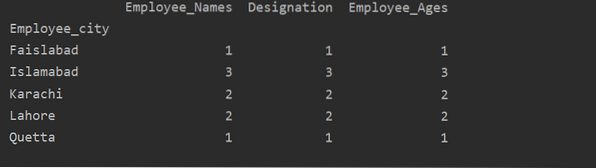
Dalam grafik yang diberikan di bawah, jumlah pekerja yang ditumpuk yang tergolong dalam bandar yang sama.
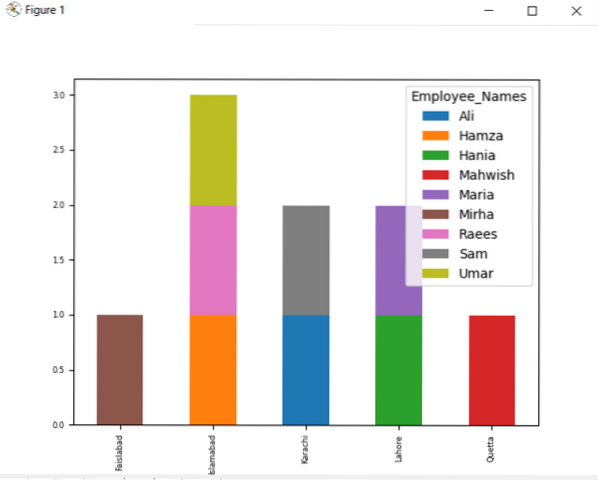
Tukar Nama Lajur dengan kumpulan mengikut
Anda juga boleh menukar nama lajur gabungan dengan beberapa nama baru yang diubah seperti berikut:
import panda sebagai pdimport matplotlib.pyplot sebagai plt
df = pd.DataFrame (
'Nama Pegawai': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Jawatan': ['Pengurus', 'Kakitangan', 'pegawai IT', 'pegawai IT', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Jawatan'].jumlah ().reset_index (nama = 'Pekerja_Perancangan')
cetak (df1)
Dalam contoh di atas, nama 'Penunjukan' diubah menjadi 'Pekerja_Perancangan'.
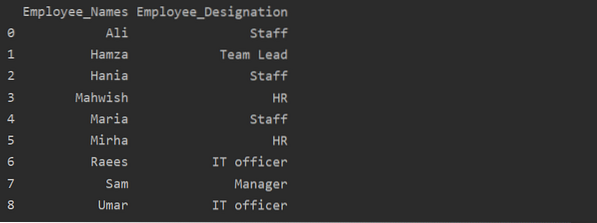
Dapatkan Kumpulan mengikut kunci atau nilai
Dengan menggunakan pernyataan kumpulan, anda boleh mengambil rekod atau nilai yang serupa dari kerangka data.
Contohnya
Dalam contoh yang diberikan di bawah ini, kami mempunyai data kumpulan berdasarkan 'Penunjukan'. Kemudian, kumpulan 'Staff' diambil dengan menggunakan .kumpulan ('Staff').
import panda sebagai pdimport matplotlib.pyplot sebagai plt
df = pd.DataFrame (
'Nama Pekerja': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Jawatan': ['Pengurus', 'Kakitangan', 'pegawai IT', 'pegawai IT', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
ekstrak_nilai = df.kumpulan ('Penunjukan')
cetak (ekstrak_nilai.get_group ('Kakitangan'))
Hasil berikut dipaparkan di tetingkap output:

Tambah Nilai ke dalam senarai kumpulan
Data serupa dapat dipaparkan dalam bentuk senarai dengan menggunakan penyataan kumpulan. Pertama, kumpulkan data berdasarkan keadaan. Kemudian, dengan menerapkan fungsi, anda boleh memasukkan kumpulan ini ke dalam senarai dengan mudah.
Contohnya
Dalam contoh ini, kami telah memasukkan rekod yang serupa ke dalam senarai kumpulan. Semua pekerja dibahagikan kepada kumpulan berdasarkan 'Employee_city', dan kemudian dengan menerapkan fungsi 'Lambda', kumpulan ini diambil dalam bentuk senarai.
import panda sebagai pddf = pd.DataFrame (
'Nama Pekerja': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Jawatan': ['Pengurus', 'Kakitangan', 'pegawai IT', 'pegawai IT', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.kumpulan oleh ('Employee_city') ['Employee_Names'].berlaku (lambda group_series: group_series.tolok ()).tetapkan semula_index ()
cetak (df1)
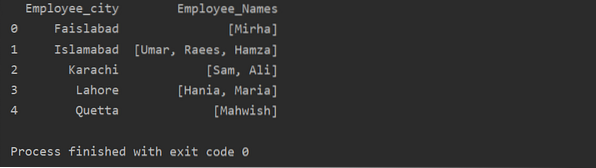
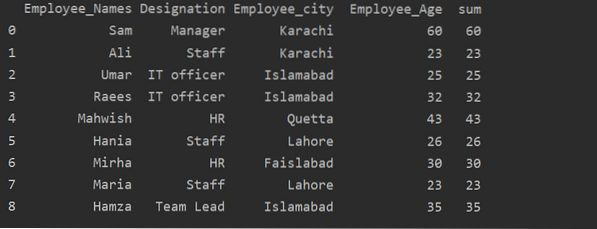
Penggunaan fungsi Transform dengan kumpulan
Pekerja dikelompokkan mengikut umur mereka, nilai-nilai ini ditambah bersama, dan dengan menggunakan fungsi 'transform' lajur baru ditambahkan dalam jadual:
import panda sebagai pddf = pd.DataFrame (
'Nama Pekerja': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Penunjukan': ['Pengurus', 'Kakitangan', 'pegawai IT', 'pegawai IT', 'HR', 'Staff', 'HR', 'Staff', 'Team Lead'],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df ['sum'] = df.kumpulan oleh (['Employee_Names']) ['Employee_Age'].ubah ('jumlah')
cetak (df)
Kesimpulannya
Kami telah meneroka pelbagai kegunaan penyataan kumpulan dengan artikel ini. Kami telah menunjukkan bagaimana anda dapat membahagikan data ke dalam kumpulan, dan dengan menerapkan agregasi atau fungsi yang berbeza, anda dapat dengan mudah mengambil kumpulan ini.


