Apache Hadoop adalah penyelesaian data besar untuk menyimpan dan menganalisis sejumlah besar data. Dalam artikel ini kami akan memperincikan langkah-langkah penyiapan yang kompleks untuk Apache Hadoop untuk memulakannya di Ubuntu secepat mungkin. Dalam catatan ini, kami akan memasang Apache Hadoop pada Ubuntu 17.10 mesin.
Versi Ubuntu
Untuk panduan ini, kami akan menggunakan Ubuntu versi 17.10 (GNU / Linux 4.13.0-38-generik x86_64).
Mengemas kini pakej yang ada
Untuk memulakan pemasangan Hadoop, kita perlu mengemas kini mesin kita dengan pakej perisian terkini yang tersedia. Kita boleh melakukan ini dengan:
sudo apt-get kemas kini && sudo apt-get -y dist-upgradeOleh kerana Hadoop menggunakan Java, kita perlu memasangnya di mesin kita. Kita dapat menggunakan versi Java apa pun di atas Java 6. Di sini, kita akan menggunakan Java 8:
sudo apt-get -y install openjdk-8-jdk-tanpa kepalaMemuat turun fail Hadoop
Semua pakej yang diperlukan kini ada di mesin kami. Kami bersedia memuat turun fail TAR Hadoop yang diperlukan supaya kami dapat memulakannya dan menjalankan program contoh dengan Hadoop juga.
Dalam panduan ini, kami akan memasang Hadoop v3.0.1. Muat turun fail yang sesuai dengan arahan ini:
wget http: // cermin.cc.kolumbia.edu / pub / perisian / apache / hadoop / common / hadoop-3.0.1 / hadoop-3.0.1.tar.gzBergantung pada kelajuan rangkaian, ini memerlukan beberapa minit kerana ukuran failnya besar:
Memuat turun Hadoop
Cari binari Hadoop terkini di sini. Setelah fail TAR dimuat turun, kita dapat mengekstrak dalam direktori semasa:
tar xvzf hadoop-3.0.1.tar.gzProses ini akan mengambil masa beberapa saat kerana saiz fail yang besar dari arkib:
Hadoop Tidak Diarkibkan
Menambah Kumpulan Pengguna Hadoop baru
Oleh kerana Hadoop beroperasi melalui HDFS, sistem fail baru dapat merosakkan sistem fail kita sendiri pada mesin Ubuntu juga. Untuk mengelakkan penggabungan ini, kami akan membuat Kumpulan Pengguna yang terpisah sepenuhnya dan memberikannya kepada Hadoop sehingga mengandungi kebenarannya sendiri. Kita boleh menambahkan kumpulan pengguna baru dengan arahan ini:
hadoop kumpulan tambahKami akan melihat seperti:
Menambah kumpulan pengguna Hadoop
Kami bersedia untuk menambahkan pengguna baru ke kumpulan ini:
useradd -G hadoopus hadoopuserHarap perhatikan bahawa semua arahan yang kita jalankan adalah pengguna root itu sendiri. Dengan arahan aove, kami dapat menambahkan pengguna baru ke kumpulan yang kami buat.
Untuk membolehkan pengguna Hadoop melakukan operasi, kami juga perlu menyediakan akses root kepadanya. Buka / etc / sudoers fail dengan arahan ini:
sudo visudoSebelum kita menambah apa-apa, fail akan kelihatan seperti:
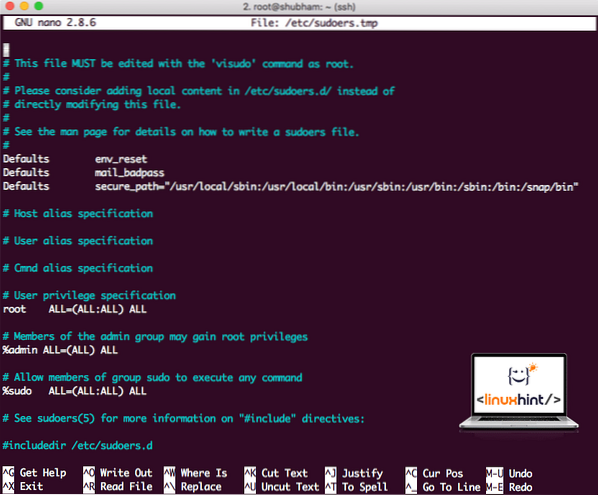
Fail Sudoers sebelum menambah apa-apa
Tambahkan baris berikut ke hujung fail:
hadoopuser SEMUA = (SEMUA) SEMUASekarang fail akan kelihatan seperti:
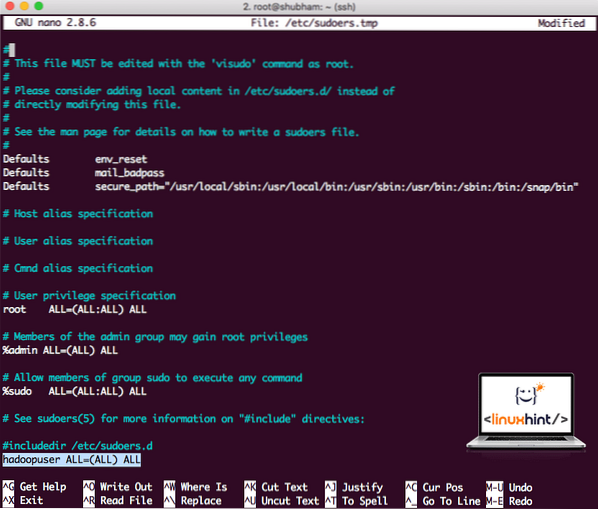
Fail Sudoers setelah menambahkan pengguna Hadoop
Ini adalah persediaan utama untuk menyediakan platform Hadoop untuk melakukan tindakan. Kami bersedia untuk menubuhkan kluster Hadoop nod tunggal sekarang.
Persediaan Node Tunggal Hadoop: Mod Berdiri
Ketika datang ke kekuatan Hadoop yang sebenarnya, biasanya disiapkan di beberapa pelayan sehingga dapat menskala di atas sejumlah besar set data yang ada di Sistem Fail Teragih Hadoop (HDFS). Ini biasanya baik dengan persekitaran debug dan tidak digunakan untuk penggunaan pengeluaran. Untuk memastikan prosesnya mudah, kami akan menerangkan bagaimana kami dapat melakukan penyediaan nod tunggal untuk Hadoop di sini.
Setelah selesai memasang Hadoop, kami juga akan menjalankan contoh aplikasi di Hadoop. Setakat ini, fail Hadoop dinamakan sebagai hadoop-3.0.1. mari namakan semula menjadi hadoop untuk penggunaan yang lebih mudah:
mv hadoop-3.0.1 hadoopFail sekarang kelihatan seperti:
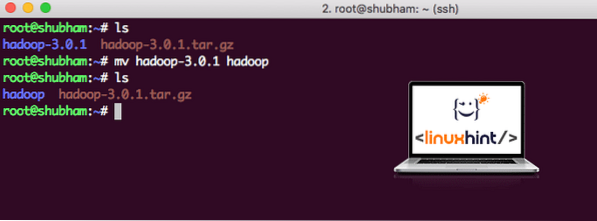
Menggerakkan Hadoop
Masa untuk menggunakan pengguna hadoop yang kita buat sebelumnya dan memberikan hak milik fail ini kepada pengguna tersebut:
chown -R hadoopuser: hadoop / root / hadoopLokasi yang lebih baik untuk Hadoop adalah direktori / usr / local /, jadi mari kita pindahkan ke sana:
mv hadoop / usr / tempatan /cd / usr / tempatan /
Menambah Hadoop ke Jalan
Untuk melaksanakan skrip Hadoop, kami akan menambahkannya ke jalan sekarang. Untuk melakukan ini, buka fail bashrc:
vi ~ /.bashrcTambahkan garis-garis ini ke hujung .fail bashrc sehingga jalan tersebut dapat mengandungi jalur fail yang dapat dieksekusi Hadoop:
# Konfigurasikan Hadoop dan Java Homeeksport HADOOP_HOME = / usr / local / hadoop
eksport JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64
eksport PATH = $ PATH: $ HADOOP_HOME / tong sampah
Fail kelihatan seperti:
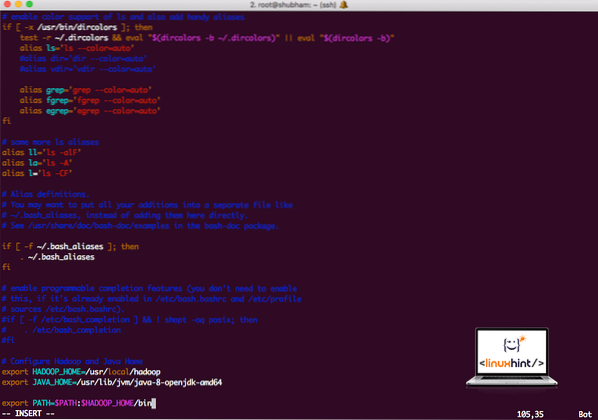
Menambah Hadoop ke Jalan
Ketika Hadoop menggunakan Java, kita perlu memberitahu fail persekitaran Hadoop hadoop-env.sh di mana ia berada. Lokasi fail ini boleh berbeza-beza berdasarkan versi Hadoop. Untuk mencari lokasi fail ini dengan mudah, jalankan perintah berikut tepat di luar direktori Hadoop:
cari hadoop / -nama hadoop-env.shKami akan mendapatkan output untuk lokasi fail:
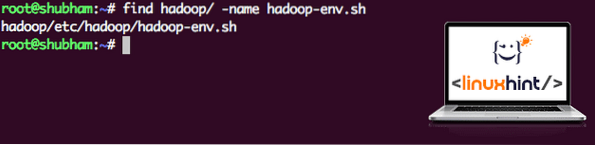
Lokasi fail persekitaran
Mari edit fail ini untuk memberitahu Hadoop mengenai lokasi Java JDK dan masukkan ini pada baris terakhir fail dan simpan:
eksport JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64Pemasangan dan penyediaan Hadoop kini selesai. Kami bersedia menjalankan aplikasi sampel kami sekarang. Tetapi tunggu, kami tidak pernah membuat contoh aplikasi!
Aplikasi Contoh Lari dengan Hadoop
Sebenarnya, pemasangan Hadoop dilengkapi dengan aplikasi sampel bawaan yang siap dijalankan setelah kita selesai memasang Hadoop. Kedengarannya bagus, betul?
Jalankan arahan berikut untuk menjalankan contoh JAR:
hadoop jar / root / hadoop / share / hadoop / mapreduce / hadoop-mapreduce-contoh-3.0.1.jar wordcount / root / hadoop / README.txt / root / OutputHadoop akan menunjukkan berapa banyak pemprosesan yang dilakukannya di simpul:
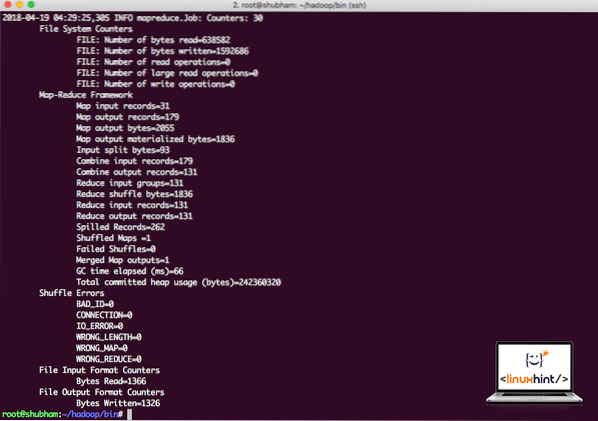
Statistik pemprosesan Hadoop
Sebaik sahaja anda melaksanakan perintah berikut, kami melihat fail part-r-00000 sebagai output. Teruskan dan lihat kandungan output:
kucing bahagian-r-00000Anda akan mendapat sesuatu seperti:
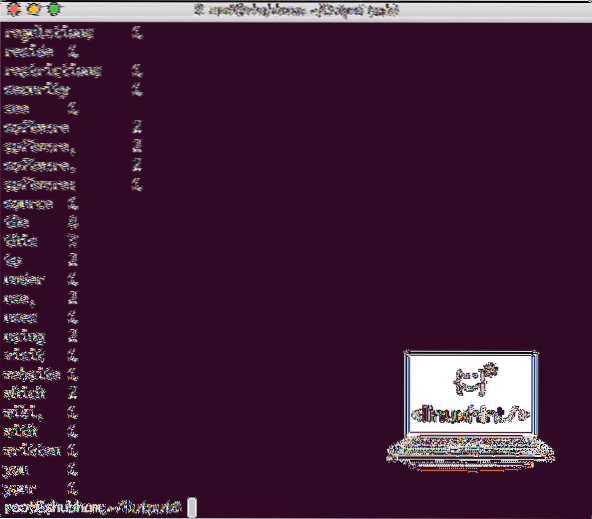
Keluaran Word Count oleh Hadoop
Kesimpulannya
Dalam pelajaran ini, kami melihat bagaimana kami dapat memasang dan mula menggunakan Apache Hadoop di Ubuntu 17.10 mesin. Hadoop sangat bagus untuk menyimpan dan menganalisis sejumlah besar data dan saya harap artikel ini dapat membantu anda mula menggunakannya di Ubuntu dengan cepat.


