Mengapa Lucene diperlukan?
Pencarian adalah salah satu operasi yang paling biasa kita lakukan berkali-kali sehari. Pencarian ini boleh merangkumi beberapa halaman web yang terdapat di Web atau aplikasi Muzik atau repositori kod atau gabungan semua ini. Seseorang mungkin berpendapat bahawa pangkalan data hubungan sederhana juga dapat menyokong pencarian. Ini adalah betul. Pangkalan data seperti MySQL menyokong carian teks penuh. Tetapi bagaimana dengan Web atau aplikasi Muzik atau repositori kod atau gabungan semua ini? Pangkalan data tidak dapat menyimpan data ini di lajurnya. Walaupun berjaya, ia memerlukan masa yang tidak dapat diterima untuk menjalankan carian sebanyak ini.
Mesin carian teks penuh mampu menjalankan pertanyaan carian pada berjuta-juta fail sekaligus. Kelajuan di mana data disimpan dalam aplikasi hari ini sangat besar. Menjalankan carian teks penuh pada jumlah data seperti ini adalah tugas yang sukar. Ini kerana maklumat yang kita perlukan mungkin ada dalam satu fail daripada berbilion fail yang disimpan di web.
Bagaimana Lucene berfungsi?
Soalan jelas yang harus anda fikirkan adalah, bagaimana Lucene begitu pantas dalam menjalankan pertanyaan carian teks penuh? Jawapan untuk ini, tentu saja, adalah dengan bantuan indeks yang dihasilkannya. Tetapi bukannya membuat indeks klasik, Lucene memanfaatkan Indeks Terbalik.
Dalam indeks klasik, untuk setiap dokumen, kami mengumpulkan senarai penuh perkataan atau istilah yang terdapat dalam dokumen tersebut. Dalam indeks terbalik, untuk setiap kata dalam semua dokumen, kami menyimpan dokumen apa dan kedudukan kata / istilah ini dapat ditemukan di. Ini adalah algoritma standard tinggi yang menjadikan carian sangat mudah. Pertimbangkan contoh berikut untuk membuat indeks klasik:
Doc1 -> "Ini", "adalah", "sederhana", "Lucene", "sampel", "klasik", "terbalik", "indeks"Doc2 -> "Running", "Elasticsearch", "Ubuntu", "Update"
Doc3 -> "RabbitMQ", "Lucene", "Kafka", "", "Spring", "Boot"
Sekiranya kita menggunakan indeks terbalik, kita akan mempunyai indeks seperti:
Ini -> (2, 71)Lucene -> (1, 9), (12,87)
Apache -> (12, 91)
Rangka Kerja -> (32, 11)
Indeks terbalik jauh lebih senang dijaga. Andaikan jika kita ingin mencari Apache dalam istilah saya, saya akan mendapat jawapan langsung dengan indeks terbalik sedangkan dengan carian klasik akan dijalankan pada dokumen lengkap yang mungkin tidak dapat dijalankan dalam senario masa nyata.
Aliran kerja Lucene
Sebelum Lucene benar-benar dapat mencari data, data perlu dilakukan. Mari gambarkan langkah-langkah ini untuk pemahaman yang lebih baik:
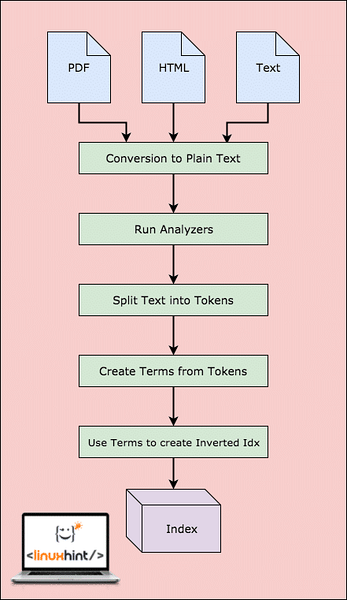
Aliran Kerja Lucene
Seperti yang ditunjukkan dalam rajah, inilah yang berlaku di Lucene:
- Lucene diberi dokumen dan sumber data lain
- Untuk setiap dokumen, Lucene terlebih dahulu menukar data ini menjadi teks biasa dan kemudian Penganalisis menukar sumber ini menjadi teks biasa
- Untuk setiap istilah dalam teks biasa, indeks terbalik dibuat
- Indeks sudah siap dicari
Dengan aliran kerja ini, Lucene adalah mesin carian teks penuh yang sangat kuat. Tetapi ini adalah satu-satunya bahagian yang dipenuhi oleh Lucene. Kita perlu melaksanakan kerja itu sendiri. Mari lihat komponen Pengindeksan yang diperlukan.
Komponen Lucene
Dalam bahagian ini, kami akan menerangkan komponen asas dan kelas asas Lucene yang digunakan untuk membuat indeks:
- Direktori: Indeks Lucene menyimpan data dalam arahan sistem fail biasa atau dalam memori jika anda memerlukan lebih banyak prestasi. Ini sepenuhnya pilihan aplikasi untuk menyimpan data di mana sahaja yang dikehendaki, Pangkalan Data, RAM atau cakera.
- Dokumen: Data yang kami berikan ke mesin Lucene perlu ditukar menjadi teks biasa. Untuk melakukan ini, kami membuat objek Dokumen yang mewakili sumber data tersebut. Kemudian, apabila kita menjalankan pertanyaan carian, sebagai hasilnya, kita akan mendapat senarai objek Dokumen yang memenuhi permintaan yang kita lalui.
- Padang: Dokumen diisi dengan koleksi Fields. Padang hanyalah sepasang (nama, nilai) barang. Oleh itu, semasa membuat objek Dokumen baru, kita perlu mengisinya dengan data berpasangan seperti itu. Apabila Medan diindeks secara terbalik, nilai Medan Tokenized dan tersedia untuk carian. Sekarang, semasa kami menggunakan Fields, tidak penting untuk menyimpan pasangan sebenar tetapi hanya indeks terbalik. Dengan cara ini, kita dapat memutuskan data apa yang dicari sahaja dan tidak penting untuk disimpan. Mari lihat contoh di sini:

Pengindeksan Medan
Dalam jadual di atas, kami memutuskan untuk menyimpan beberapa ladang dan yang lain tidak disimpan. Medan badan tidak disimpan tetapi diindeks. Ini bermaksud bahawa e-mel akan dikembalikan sebagai hasilnya apabila pertanyaan untuk salah satu Syarat untuk isi kandungan dijalankan.
- Syarat: Istilah mewakili perkataan dari teks. Istilah diekstrak dari analisis dan tokenisasi nilai Fields, dengan demikian Istilah adalah unit terkecil di mana carian dijalankan.
- Penganalisis: Penganalisis adalah bahagian terpenting dalam proses pengindeksan dan pencarian. Penganalisislah yang mengubah teks biasa menjadi Token dan Syarat sehingga dapat dicari. Itu bukan satu-satunya tanggungjawab Penganalisis. Penganalisis menggunakan Tokenizer untuk membuat Token. Penganalisis juga melakukan tugas-tugas berikut:
- Stemming: Penganalisis menukar perkataan menjadi Stem. Ini bermaksud 'bunga' ditukar menjadi kata pokok 'bunga'. Oleh itu, apabila carian untuk 'bunga' dijalankan, dokumen akan dikembalikan.
- Menyaring: Penganalisis juga menapis kata berhenti seperti 'The', 'is' dll. kerana kata-kata ini tidak menarik sebarang pertanyaan untuk dijalankan dan tidak produktif.
- Normalisasi: Proses ini menghilangkan aksen dan tanda watak lain.
Ini hanyalah tanggungjawab biasa StandardAnalyzer.
Contoh Permohonan
Kami akan menggunakan salah satu daripada banyak pola dasar Maven untuk membuat contoh projek untuk contoh kami. Untuk membuat projek, jalankan perintah berikut dalam direktori yang akan anda gunakan sebagai ruang kerja:
pola dasar mvn: menghasilkan -DgroupId = com.linuxhint.contoh -DartifactId = LH-LuceneContoh -DarchetypeArtifactId = maven-archetype-quickstart -DinteractiveMode = falseSekiranya anda menjalankan maven untuk pertama kalinya, diperlukan beberapa saat untuk menyelesaikan arahan menghasilkan kerana maven harus memuat turun semua plugin dan artifak yang diperlukan untuk membuat tugas penjanaan. Inilah rupa output projek:
Penyediaan Projek
Setelah anda membuat projek, jangan ragu untuk membukanya di IDE kegemaran anda. Langkah seterusnya adalah menambahkan Dependensi Maven yang sesuai untuk projek tersebut. Inilah pom.fail xml dengan pergantungan yang sesuai:
Akhirnya, untuk memahami semua JAR yang ditambahkan ke dalam projek ketika kita menambahkan kebergantungan ini, kita dapat menjalankan perintah Maven yang mudah yang memungkinkan kita melihat Pokok Dependensi lengkap untuk sebuah projek ketika kita menambahkan beberapa kebergantungan padanya. Berikut adalah arahan yang boleh kita gunakan:
kebergantungan mvn: pokokApabila kita menjalankan perintah ini, ia akan menunjukkan kepada kita Pokok Ketergantungan berikut: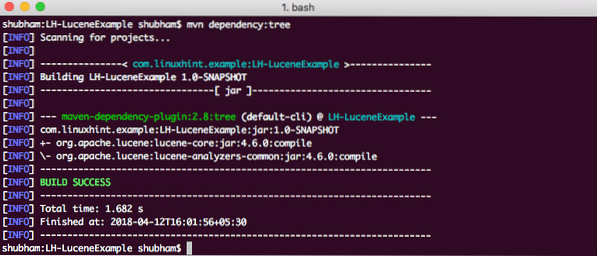
Akhirnya, kami membuat kelas SimpleIndexer yang berjalan
import java.io.Fail;
import java.io.Pembaca Fail;
import java.io.IOException;
org import.apache.lucene.analisis.Penganalisis;
org import.apache.lucene.analisis.standard.StandardAnalyzer;
org import.apache.lucene.dokumen.Dokumen;
org import.apache.lucene.dokumen.StoredField;
org import.apache.lucene.dokumen.Bidang Teks;
org import.apache.lucene.indeks.Penulis Indeks;
org import.apache.lucene.indeks.IndexWriterConfig;
org import.apache.lucene.kedai.Direktori FS;
org import.apache.lucene.guna.Versi;
kelas awam SimpleIndexer
Indeks String akhir statik persendirianDirectory = "/ Pengguna / shubham / tempat / LH-LuceneContoh / Indeks";
rentetan akhir statik persendirian dirToBeIndexed = "/ Pengguna / shubham / tempat / LH-LuceneContoh / src / main / java / com / linuxhint / contoh";
main statik kekosongan awam (String [] args) membuang Pengecualian
File indexDir = fail baru (indexDirectory);
Data fileDir = Fail baru (dirToBeIndexed);
SimpleIndexer indexer = SimpleIndexer baru ();
int numIndexed = pengindeks.indeks (indexDir, dataDir);
Sistem.keluar.println ("Jumlah fail yang diindeks" + numIndexed);
indeks int peribadi (File indexDir, File dataDir) melemparkan IOException
Penganalisis penganalisis = StandardAnalyzer baru (Versi.LUCENE_46);
IndexWriterConfig config = IndexWriterConfig baru (Versi.LUCENE_46,
penganalisis);
IndexWriter indexWriter = IndexWriter baru (FSDirectory.terbuka (indexDir),
konfigurasi);
Fail [] fail = dataDir.listFiles ();
untuk (Fail f: fail)
Sistem.keluar.println ("Fail pengindeksan" + f.getCanonicalPath ());
Dokumen dokumen = Dokumen baru ();
dokumen.tambah (TextField baru ("kandungan", FileReader baru (f)));
dokumen.tambah (StoredField baru ("fileName", f.getCanonicalPath ()));
indexWriter.addDocument (doc);
int numIndexed = indexWriter.maxDoc ();
indexWriter.tutup ();
pulangkan numIndexed;
Dalam kod ini, kami baru saja membuat contoh Dokumen dan menambahkan Medan baru yang mewakili kandungan Fail. Inilah output yang kami dapat semasa menjalankan fail ini:
Fail pengindeksan / Pengguna / shubham / tempat / LH-LuceneContoh / src / main / java / com / linuxhint / example / SimpleIndexer.jawaJumlah fail yang diindeks 1
Juga, direktori baru dibuat di dalam projek dengan kandungan berikut:
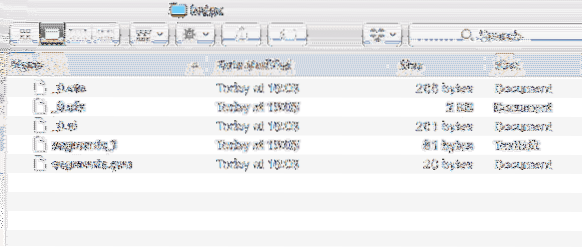
Data Indeks
Kami akan menganalisis semua fail yang dibuat dalam Indeks ini dalam lebih banyak pelajaran yang akan datang di Lucene.
Kesimpulannya
Dalam pelajaran ini, kami melihat bagaimana Apache Lucene berfungsi dan kami juga membuat aplikasi contoh ringkas yang berdasarkan Maven dan java.


