Sebagai contoh, perniagaan mungkin menjalankan mesin analisis teks yang memproses tweet mengenai perniagaannya yang menyebutkan nama syarikat, lokasi, proses dan menganalisis emosi yang berkaitan dengan tweet itu. Tindakan yang betul dapat diambil lebih cepat jika perniagaan itu mengetahui tentang berkembangnya tweet negatif untuknya di lokasi tertentu untuk menyelamatkan dirinya dari kesalahan atau apa pun. Contoh biasa lain akan Youtube. Pentadbir dan moderator Youtube mengetahui tentang kesan video bergantung pada jenis komen yang dibuat pada video atau mesej sembang video. Ini akan membantu mereka mencari kandungan yang tidak sesuai di laman web dengan lebih pantas kerana sekarang, mereka telah menghapus kerja manual dan menggunakan bot analisis teks pintar automatik.
Dalam pelajaran ini, kita akan mengkaji beberapa konsep yang berkaitan dengan analisis teks dengan bantuan perpustakaan NLTK di Python. Beberapa konsep ini akan melibatkan:
- Tokenization, cara memecahkan sekeping teks menjadi kata, ayat
- Mengelakkan kata berhenti berdasarkan bahasa Inggeris
- Melakukan penangkapan dan penegasan pada sekeping teks
- Mengenal pasti token yang akan dianalisis
NLP akan menjadi bidang fokus utama dalam pelajaran ini kerana dapat digunakan untuk senario kehidupan nyata yang sangat besar di mana ia dapat menyelesaikan masalah besar dan penting. Sekiranya anda fikir ini terdengar rumit, memang betul tetapi konsepnya juga mudah difahami jika anda mencuba contoh berdampingan. Mari kita pasang NLTK pada mesin anda untuk memulakannya.
Memasang NLTK
Sekadar catatan sebelum memulakan, anda boleh menggunakan persekitaran maya untuk pelajaran ini yang boleh kita buat dengan arahan berikut:
python -m virtualenv nltksumber nltk / bin / aktifkan
Setelah persekitaran maya aktif, anda boleh memasang perpustakaan NLTK dalam env maya sehingga contoh yang kami buat seterusnya dapat dilaksanakan:
memasang pip nltkKami akan memanfaatkan Anaconda dan Jupyter dalam pelajaran ini. Sekiranya anda ingin memasangnya di mesin anda, lihat pelajaran yang menerangkan “Cara Memasang Anaconda Python di Ubuntu 18.04 LTS ”dan kongsi maklum balas anda sekiranya anda menghadapi sebarang masalah. Untuk memasang NLTK dengan Anaconda, gunakan arahan berikut di terminal dari Anaconda:
conda install -c anaconda nltkKami melihat sesuatu seperti ini semasa kami melaksanakan perintah di atas:
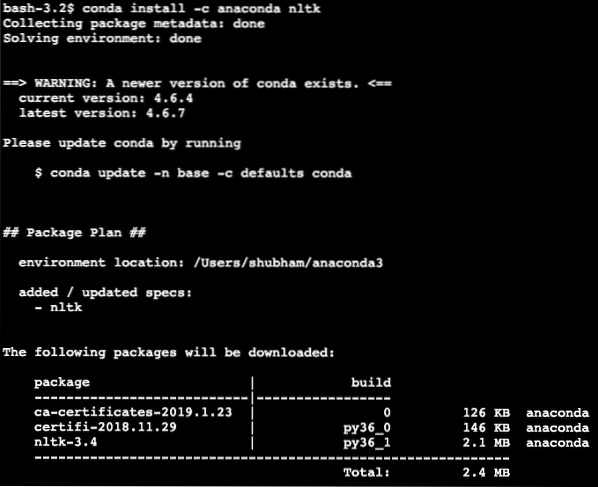
Setelah semua pakej yang diperlukan dipasang dan selesai, kita dapat mulai menggunakan perpustakaan NLTK dengan pernyataan import berikut:
import nltkMari mulakan dengan contoh asas NLTK sekarang kerana kami telah memasang pakej prasyarat.
Tokenisasi
Kami akan memulakan dengan Tokenization yang merupakan langkah pertama dalam melakukan analisis teks. Token boleh menjadi bahagian yang lebih kecil dari sekeping teks yang dapat dianalisis. Terdapat dua jenis Tokenization yang dapat dilakukan dengan NLTK:
- Tokenisasi Kalimat
- Token Perkataan
Anda boleh meneka apa yang berlaku pada setiap Tokenization jadi mari kita selami contoh kod.
Tokenisasi Kalimat
Seperti namanya, Sentence Tokenizers membahagikan sekeping teks menjadi ayat. Mari cuba coretan kod mudah untuk yang sama di mana kita menggunakan teks yang kita pilih dari tutorial Apache Kafka. Kami akan melakukan import yang diperlukan
import nltkdari nltk.tokenize import sent_tokenize
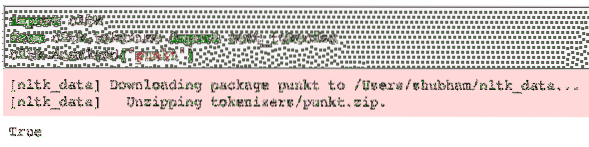
Harap maklum bahawa anda mungkin menghadapi ralat kerana hilangnya ketergantungan untuk nltk dipanggil punkt. Tambahkan baris berikut tepat selepas pengimportan dalam program untuk mengelakkan sebarang amaran:
nltk.muat turun ('punkt')Bagi saya, ia memberikan output berikut:
Seterusnya, kami menggunakan tokenizer ayat yang kami import:
text = "" "Topik dalam Kafka adalah sesuatu di mana mesej dihantar. Penggunaaplikasi yang berminat dalam topik itu menarik mesej di dalamnya
topik dan boleh melakukan apa sahaja dengan data tersebut. Sehingga masa tertentu, sebilangan besar
aplikasi pengguna dapat menarik mesej ini berkali-kali."" "
ayat = dihantar_tokenize (teks)
cetak (ayat)
Kami melihat sesuatu seperti ini semasa kami melaksanakan skrip di atas:

Seperti yang dijangkakan, teks itu disusun dengan betul menjadi ayat.
Token Perkataan
Seperti namanya, Word Tokenizers memecahkan sebilangan teks menjadi kata-kata. Mari cuba coretan kod ringkas untuk teks yang sama dengan contoh sebelumnya:
dari nltk.tokenize import word_tokenizeperkataan = word_tokenize (teks)
mencetak (perkataan)
Kami melihat sesuatu seperti ini semasa kami melaksanakan skrip di atas:

Seperti yang dijangkakan, teks disusun dengan betul menjadi kata-kata.
Taburan Kekerapan
Sekarang kita telah memecahkan teks, kita juga dapat mengira frekuensi setiap kata dalam teks yang kita gunakan. Sangat mudah dilakukan dengan NLTK, berikut adalah coretan kod yang kami gunakan:
dari nltk.kebarangkalian import FreqDistsebaran = FreqDist (perkataan)
cetak (sebaran)
Kami melihat sesuatu seperti ini semasa kami melaksanakan skrip di atas:

Seterusnya, kita dapat mencari kata-kata yang paling umum dalam teks dengan fungsi mudah yang menerima jumlah kata yang akan ditunjukkan:
# Perkataan yang paling biasapengedaran.paling_kebiasaan (2)
Kami melihat sesuatu seperti ini semasa kami melaksanakan skrip di atas:

Akhirnya, kita dapat membuat plot pengedaran frekuensi untuk membersihkan kata-kata dan kiraannya dalam teks yang diberikan dan memahami dengan jelas sebaran perkataan:

Kata kunci
Sama seperti ketika kita bercakap dengan orang lain melalui panggilan, ada kebisingan mengenai panggilan yang merupakan maklumat yang tidak diingini. Dengan cara yang sama, teks dari dunia nyata juga mengandungi suara yang disebut sebagai Kata kunci. Kata kunci boleh berbeza-beza dari bahasa ke bahasa tetapi ia dapat dikenali dengan mudah. Beberapa Kata Laluan dalam bahasa Inggeris boleh - adalah, adalah, a, dll.
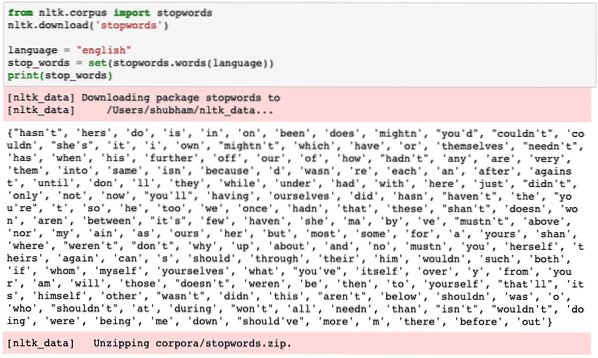
Kita dapat melihat kata-kata yang dianggap sebagai Kata Kunci oleh NLTK untuk bahasa Inggeris dengan coretan kod berikut:
dari nltk.kata laluan import korpusnltk.muat turun ('kata laluan')
bahasa = "english"
stop_words = set (kata laluan.perkataan (bahasa))
cetak (kata kunci berhenti)
Sudah tentu set kata berhenti boleh menjadi besar, ia disimpan sebagai set data yang terpisah yang boleh dimuat turun dengan NLTK seperti yang ditunjukkan di atas. Kami melihat sesuatu seperti ini semasa kami melaksanakan skrip di atas:
Kata berhenti ini harus dikeluarkan dari teks jika anda ingin melakukan analisis teks yang tepat untuk bahagian teks yang disediakan. Mari keluarkan kata berhenti dari token teks kami:
disaring_words = []untuk perkataan dalam perkataan:
jika perkataan tidak dalam stop_words:
kata kunci yang ditapis.tambahkan (perkataan)
kata kunci yang ditapis
Kami melihat sesuatu seperti ini semasa kami melaksanakan skrip di atas:

Kata Pemeri
Batang kata adalah asas kata itu. Sebagai contoh:
Kami akan beraksi berdasarkan kata-kata yang disaring dari mana kami membuang kata berhenti di bahagian terakhir. Mari tulis coretan kod ringkas di mana kita menggunakan stemmer NLTK untuk melakukan operasi:
dari nltk.batang import PorterStemmerps = PorterStemmer ()
stemmed_words = []
untuk perkataan dalam kata kunci yang disaring:
kata kunci berpunca.tambahkan (ps.batang (perkataan))
cetak ("Stemmed Sentence:", stemmed_words)
Kami melihat sesuatu seperti ini semasa kami melaksanakan skrip di atas:

Penandaan POS
Langkah seterusnya dalam analisis teks adalah selepas mengenal pasti adalah mengenal pasti dan mengelompokkan setiap perkataan dari segi nilainya, i.e. jika setiap perkataan itu adalah kata nama atau kata kerja atau sesuatu yang lain. Ini disebut sebagai Bahagian Penandaan Ucapan. Mari lakukan penandaan POS sekarang:
token = nltk.word_tokenize (ayat [0])cetak (token)
Kami melihat sesuatu seperti ini semasa kami melaksanakan skrip di atas:

Sekarang, kita dapat melakukan penandaan, yang mana kita harus memuat turun set data lain untuk mengenal pasti teg yang betul:
nltk.muat turun ('averaged_perceptron_tagger')nltk.pos_tag (token)
Berikut adalah output penandaan:
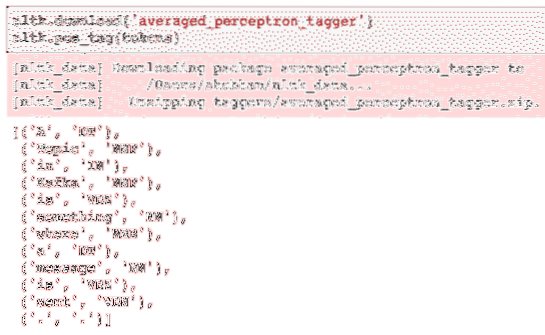
Sekarang kita akhirnya dapat mengenal pasti kata-kata yang ditandai, ini adalah set data di mana kita dapat melakukan analisis sentimen untuk mengenal pasti emosi di sebalik ayat.
Kesimpulannya
Dalam pelajaran ini, kami melihat pakej bahasa semula jadi yang sangat baik, NLTK yang membolehkan kami bekerja dengan data teks tidak berstruktur untuk mengenal pasti kata-kata berhenti dan melakukan analisis yang lebih mendalam dengan menyiapkan satu set data tajam untuk analisis teks dengan perpustakaan seperti sklearn.
Cari semua kod sumber yang digunakan dalam pelajaran ini di Github. Sila kongsi maklum balas anda mengenai pelajaran di Twitter dengan @sbmaggarwal dan @LinuxHint.


