Dalam pelajaran ini, itulah yang ingin kita lakukan. Kami akan mengetahui bagaimana nilai tag HTML yang berbeza dapat diekstrak dan juga mengatasi fungsi lalai modul ini untuk menambahkan beberapa logik kami sendiri. Kami akan melakukan ini dengan menggunakan Penyusun HTML kelas di Python di html.menghuraikan modul. Mari lihat kodnya dalam tindakan.
Melihat kelas HTMLParser
Untuk menguraikan teks HTML di Python, kita dapat memanfaatkannya Penyusun HTML kelas di html.menghuraikan modul. Mari lihat definisi kelas untuk Penyusun HTML kelas:
kelas html.menghuraikan.HTMLParser (*, convert_charrefs = True)The menukar_charrefs bidang, jika ditetapkan ke True akan menjadikan semua rujukan watak ditukar kepada setara Unicode mereka. Hanya yang skrip / gaya elemen tidak ditukar. Sekarang, kami akan cuba memahami setiap fungsi untuk kelas ini juga untuk lebih memahami apa yang dilakukan oleh setiap fungsi.
- handle_startendtag Ini adalah fungsi pertama yang dipicu ketika rentetan HTML diteruskan ke instance kelas. Setelah teks sampai di sini, kawalan diteruskan ke fungsi lain di kelas yang menyempit ke tag lain di Rentetan. Ini juga jelas dalam definisi untuk fungsi ini: def handle_startendtag (self, tag, attrs):
diri.handle_starttag (teg, atrs)
diri.handle_endtag (teg) - handle_starttag: Kaedah ini menguruskan tag permulaan untuk data yang diterimanya. Definisi adalah seperti yang ditunjukkan di bawah: def handle_starttag (self, tag, attrs):
lulus - handle_endtag: Kaedah ini menguruskan tag akhir untuk data yang diterimanya: def handle_endtag (self, tag):
lulus - mengendalikan_charref: Kaedah ini menguruskan rujukan watak dalam data yang diterimanya. Definisi adalah seperti yang ditunjukkan di bawah: def handle_charref (diri, nama):
lulus - handle_entityref: Fungsi ini menangani rujukan entiti dalam HTML yang diteruskan kepadanya: def handle_entityref (diri, nama):
lulus - mengendalikan_data: Ini adalah fungsi di mana kerja nyata dilakukan untuk mengekstrak nilai dari tag HTML dan menyampaikan data yang berkaitan dengan setiap tag. Definisinya adalah seperti di bawah: def handle_data (diri, data):
lulus - menangani_komen: Dengan menggunakan fungsi ini, kita juga dapat mendapatkan komen yang dilampirkan pada sumber HTML: def handle_comment (diri, data):
lulus - pemegang_pi: Oleh kerana HTML juga boleh mempunyai arahan pemprosesan, ini adalah fungsi di mana definisi ini seperti yang ditunjukkan di bawah: def handle_pi (diri, data)
lulus - mengendalikan_decl: Kaedah ini menangani deklarasi dalam HTML, definisinya diberikan sebagai: def handle_decl (self, Dec):
lulus
Mengkelas kelas HTMLParser
Di bahagian ini, kita akan sub-class HTMLParser class dan akan melihat beberapa fungsi yang dipanggil ketika data HTML diteruskan ke instance kelas. Mari tulis skrip ringkas yang melakukan semua ini:
dari html.parser import HTMLParserkelas LinuxHTMLParser (HTMLParser):
def handle_starttag (diri, tag, atrs):
cetak ("Tanda mula ditemui:", tag)
def handle_endtag (diri, tag):
cetak ("Tanda akhir ditemui:", tag)
def handle_data (diri, data):
cetak ("Data dijumpai:", data)
parser = LinuxHTMLParser ()
menghuraikan.makanan ("
'
Modul penghuraian HTML Python
')
Inilah yang kita dapat kembali dengan arahan ini:
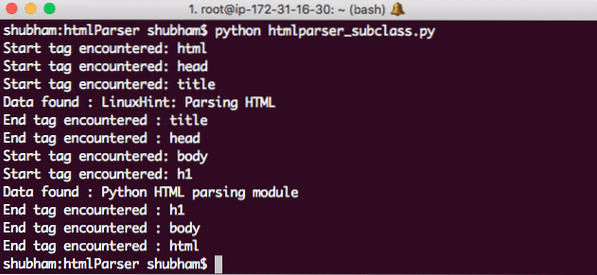
Subkelas Python HTMLParser
Fungsi HTMLParser
Di bahagian ini, kami akan bekerjasama dengan pelbagai fungsi kelas HTMLParser dan melihat fungsi masing-masing:
dari html.parser import HTMLParserdari html.entiti import nama2codepoint
kelas LinuxHint_Parse (HTMLParser):
def handle_starttag (diri, tag, atrs):
cetak ("Tanda mula:", teg)
untuk attr dalam attrs:
cetak ("attr:", attr)
def handle_endtag (diri, tag):
cetak ("Tanda akhir:", tag)
def handle_data (diri, data):
cetak ("Data:", data)
def handle_comment (diri, data):
cetak ("Komen:", data)
def handle_entityref (diri, nama):
c = chr (name2codepoint [nama])
cetak ("Dinamakan ent:", c)
def handle_charref (diri, nama):
sekiranya nama.startswith ('x'):
c = chr (int (nama [1:], 16))
lain:
c = chr (int (nama))
cetak ("Num ent:", c)
def handle_decl (diri, data):
cetak ("Decl:", data)
parser = LinuxHint_Parse ()
Dengan pelbagai panggilan, marilah kita memberi makan data HTML yang terpisah untuk contoh ini dan melihat output apa yang dihasilkan oleh panggilan ini. Kita akan mulakan dengan sederhana DOCTYPE tali:
menghuraikan.makanan (''"http: // www.w3.org / TR / html4 / ketat.dtd "> ')Inilah yang kami dapat dengan panggilan ini:
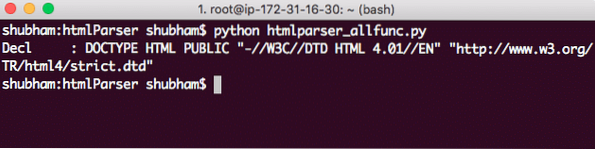
Rentetan DOCTYPE
Sekarang mari kita mencuba tag gambar dan melihat data yang diekstraknya:
menghuraikan.makanan (' ')
') Inilah yang kami dapat dengan panggilan ini:

Teg gambar HTMLParser
Seterusnya, mari cuba bagaimana tag skrip berkelakuan dengan fungsi Python:
menghuraikan.makanan ('')menghuraikan.makanan ('')
menghuraikan.suapan ('# python color: green')
Inilah yang kami dapat dengan panggilan ini:

Teg skrip di htmlparser
Akhirnya, kami menyampaikan komen ke bahagian HTMLParser juga:
menghuraikan.makanan ('''')
Inilah yang kami dapat dengan panggilan ini:

Menghuraikan komen
Kesimpulannya
Dalam pelajaran ini, kami melihat bagaimana kami dapat menguraikan HTML menggunakan kelas HTMLParser Python sendiri tanpa perpustakaan lain. Kita boleh mengubah kod dengan mudah untuk mengubah sumber data HTML menjadi klien HTTP.
Baca lebih banyak catatan berdasarkan Python di sini.


