
Ketika saya mula bekerja dengan masalah pembelajaran mesin, maka saya merasa panik algoritma mana yang harus saya gunakan? Atau mana yang senang digunakan? Sekiranya anda seperti saya, maka artikel ini dapat membantu anda mengetahui tentang kecerdasan buatan dan algoritma, kaedah, atau teknik pembelajaran mesin untuk menyelesaikan masalah yang tidak dijangka atau yang dijangkakan.
Pembelajaran mesin adalah teknik AI yang kuat yang dapat melaksanakan tugas dengan berkesan tanpa menggunakan arahan yang jelas. Model ML dapat belajar dari data dan pengalamannya. Aplikasi pembelajaran mesin automatik, mantap, dan dinamik. Beberapa algoritma dikembangkan untuk mengatasi sifat dinamik masalah kehidupan nyata ini. Secara amnya, terdapat tiga jenis algoritma pembelajaran mesin seperti pembelajaran diawasi, pembelajaran tanpa pengawasan, dan pembelajaran pengukuhan.
Algoritma Pembelajaran Mesin & AI Terbaik
Memilih teknik atau kaedah pembelajaran mesin yang sesuai adalah salah satu tugas utama untuk mengembangkan projek kecerdasan buatan atau pembelajaran mesin. Kerana terdapat beberapa algoritma yang tersedia, dan semuanya mempunyai faedah dan kegunaannya. Di bawah ini kami nyatakan 20 algoritma pembelajaran mesin untuk pemula dan profesional. Oleh itu, mari kita lihat.
1. Naive Bayes
Pengelaskan Naïve Bayes adalah pengklasifikasi probabilistik berdasarkan teorema Bayes, dengan anggapan kebebasan antara ciri. Ciri-ciri ini berbeza dari aplikasi ke aplikasi. Ini adalah salah satu kaedah pembelajaran mesin yang selesa untuk dilatih oleh pemula.
Naïve Bayes adalah model kebarangkalian bersyarat. Diberikan contoh masalah untuk diklasifikasikan, diwakili oleh vektor x = (xi … Xn) mewakili beberapa ciri n (pemboleh ubah bebas), ia memberikan kebarangkalian contoh semasa untuk setiap hasil K yang berpotensi:
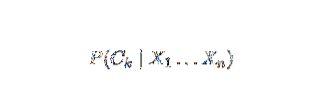 Masalah dengan rumusan di atas adalah bahawa jika jumlah ciri n signifikan atau jika elemen dapat mengambil sejumlah besar nilai, maka mendasarkan model seperti itu pada jadual kebarangkalian tidak dapat dilaksanakan. Oleh itu, kami membangunkan semula model agar lebih mudah dikendalikan. Dengan menggunakan teorema Bayes, kebarangkalian bersyarat boleh ditulis sebagai,
Masalah dengan rumusan di atas adalah bahawa jika jumlah ciri n signifikan atau jika elemen dapat mengambil sejumlah besar nilai, maka mendasarkan model seperti itu pada jadual kebarangkalian tidak dapat dilaksanakan. Oleh itu, kami membangunkan semula model agar lebih mudah dikendalikan. Dengan menggunakan teorema Bayes, kebarangkalian bersyarat boleh ditulis sebagai,
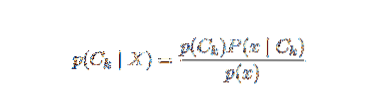
Dengan menggunakan istilah kebarangkalian Bayesian, persamaan di atas boleh ditulis sebagai:
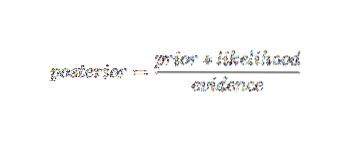
Algoritma kecerdasan buatan ini digunakan dalam klasifikasi teks, i.e., analisis sentimen, pengkategorian dokumen, penyaringan spam, dan klasifikasi berita. Teknik pembelajaran mesin ini berfungsi dengan baik jika data input dikategorikan ke dalam kumpulan yang telah ditentukan. Ia juga memerlukan lebih sedikit data daripada regresi logistik. Ia mengatasi pelbagai domain.
2. Mesin Vektor Sokongan
Support Vector Machine (SVM) adalah salah satu algoritma pembelajaran mesin diselia yang paling banyak digunakan dalam bidang klasifikasi teks. Kaedah ini juga digunakan untuk regresi. Ia juga dapat disebut sebagai Rangkaian Vektor Sokongan. Cortes & Vapnik mengembangkan kaedah ini untuk pengkelasan binari. Model pembelajaran yang diawasi adalah pendekatan pembelajaran mesin yang menyimpulkan output dari data latihan berlabel.
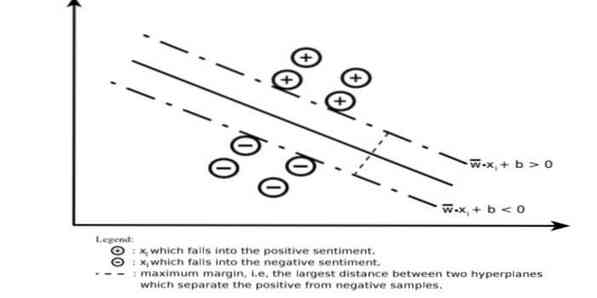
Mesin vektor sokongan membina hiperplane atau set hyperplane di kawasan yang sangat tinggi atau dimensi tak terhingga. Ia mengira permukaan pemisahan linier dengan margin maksimum untuk satu set latihan yang diberikan.
Hanya sebahagian daripada vektor input yang akan mempengaruhi pilihan margin (dilingkari dalam gambar); vektor seperti itu disebut vektor sokongan. Apabila permukaan pemisahan linear tidak wujud, misalnya, dengan adanya data yang bising, algoritma SVM dengan pemboleh ubah kendur sesuai. Pengelaskan ini cuba membahagikan ruang data dengan menggunakan persamaan linear atau bukan linear antara kelas yang berbeza.
SVM telah digunakan secara meluas dalam masalah klasifikasi corak dan regresi nonlinier. Juga, ini adalah salah satu teknik terbaik untuk melakukan pengkategorian teks automatik. Perkara terbaik mengenai algoritma ini ialah ia tidak membuat andaian kuat terhadap data.
Untuk melaksanakan Mesin Vektor Sokongan: Perpustakaan Sains data di Python- SciKit Learn, PyML, SVMStruktur Python, LIBSVM dan Perpustakaan Sains data di R-Klar, e1071.
3. Regresi Linear
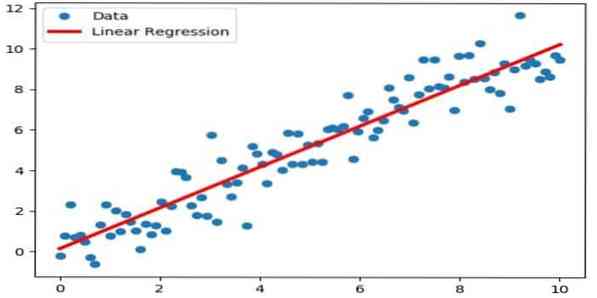
Regresi linier adalah pendekatan langsung yang digunakan untuk memodelkan hubungan antara pemboleh ubah bersandar dan satu atau lebih pemboleh ubah bebas. Sekiranya terdapat satu pemboleh ubah bebas, maka ia dipanggil regresi linear sederhana. Sekiranya terdapat lebih daripada satu pemboleh ubah bebas, maka ini disebut regresi linear berganda.
Rumus ini digunakan untuk menganggarkan nilai sebenar seperti harga rumah, jumlah panggilan, jumlah penjualan berdasarkan pemboleh ubah berterusan. Di sini, hubungan antara pemboleh ubah bebas dan bersandar dijalin dengan memasang garis terbaik. Garis paling sesuai ini dikenali sebagai garis regresi dan diwakili oleh persamaan linear
Y = a * X + b.
di sini,
- Pemboleh ubah bersandar Y
- a - cerun
- X - pemboleh ubah bebas
- b - pintasan
Kaedah pembelajaran mesin ini senang digunakan. Ia dilaksanakan dengan pantas. Ini boleh digunakan dalam perniagaan untuk ramalan penjualan. Ia juga boleh digunakan dalam penilaian risiko.
4. Regresi Logistik
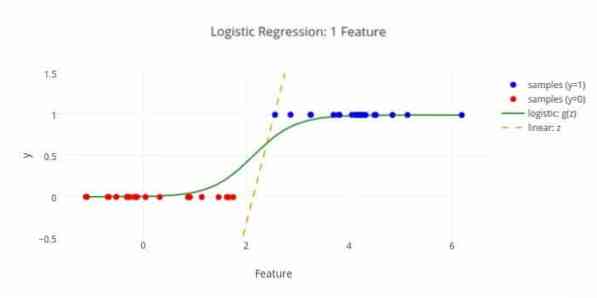
Berikut adalah algoritma pembelajaran mesin lain - regresi logistik atau regresi logit yang digunakan untuk menganggarkan nilai diskrit (Nilai binari seperti 0/1, ya / tidak, benar / salah) berdasarkan satu set pemboleh ubah bebas yang diberikan. Tugas algoritma ini adalah untuk meramalkan kebarangkalian kejadian dengan memasukkan data ke fungsi logit. Nilai outputnya terletak di antara 0 dan 1.
Rumusannya dapat digunakan dalam berbagai bidang seperti pembelajaran mesin, disiplin ilmiah, dan bidang perubatan. Ia dapat digunakan untuk meramalkan bahaya terjadinya penyakit tertentu berdasarkan ciri-ciri pesakit yang diperhatikan. Regresi logistik dapat digunakan untuk ramalan keinginan pelanggan untuk membeli produk. Teknik pembelajaran mesin ini digunakan dalam ramalan cuaca untuk meramalkan kebarangkalian hujan.
Regresi logistik dapat dibahagikan kepada tiga jenis -
- Regresi Logistik Perduaan
- Regresi Logistik berbilang nominal
- Regresi Logistik Biasa
Regresi logistik kurang rumit. Juga kuat. Ia dapat mengatasi kesan tidak linear. Walau bagaimanapun, jika data latihan jarang dan dimensi tinggi, algoritma ML ini mungkin berlebihan. Ia tidak dapat meramalkan hasil berterusan.
5. Jiran terdekat-K (KNN)
K-terdekat-jiran (kNN) adalah pendekatan statistik yang terkenal untuk klasifikasi dan telah banyak dikaji selama bertahun-tahun, dan telah menerapkan awal untuk tugas pengkategorian. Ia bertindak sebagai metodologi bukan parametrik untuk masalah klasifikasi dan regresi.
Kaedah AI dan ML ini agak mudah. Ini menentukan kategori dokumen ujian t berdasarkan pengundian sekumpulan dokumen k yang paling dekat dengan t dari segi jarak, biasanya jarak Euclidean. Peraturan keputusan penting yang diberikan dokumen pengujian t untuk pengelasan kNN adalah:
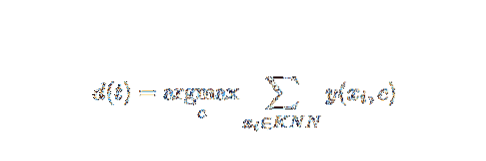
Di mana y (xi, c) adalah fungsi klasifikasi binari untuk dokumen latihan xi (yang mengembalikan nilai 1 jika xi dilabelkan dengan c, atau 0 sebaliknya), peraturan ini melabel t dengan kategori yang diberi suara terbanyak di k -kawasan kejiranan.
Kita boleh dipetakan KNN ke kehidupan sebenar kita. Sebagai contoh, jika anda ingin mengetahui sebilangan orang, di antaranya anda tidak mendapat maklumat, anda mungkin lebih suka membuat keputusan mengenai rakan-rakan terdekatnya dan oleh itu kalangan yang dia masuki dan mendapatkan akses kepada maklumatnya. Algoritma ini mahal.
6. K-bermaksud
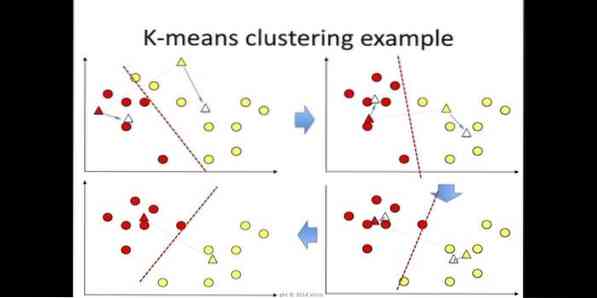
k-means clustering adalah kaedah pembelajaran tanpa pengawasan yang dapat diakses untuk analisis kluster dalam perlombongan data. Tujuan algoritma ini adalah untuk membahagikan n pemerhatian ke dalam kluster k di mana setiap pemerhatian tergolong dalam min kluster terdekat. Algoritma ini digunakan dalam segmentasi pasar, visi komputer, dan astronomi di antara banyak domain lain.
7. Pokok keputusan
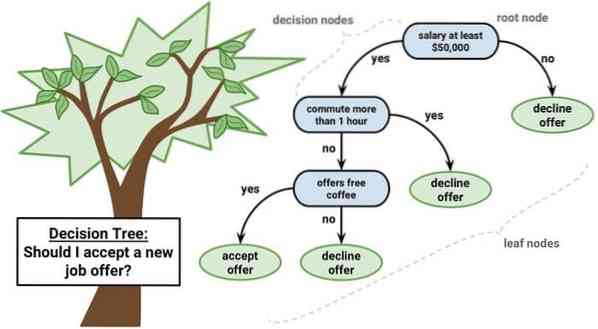
Pokok keputusan adalah alat sokongan keputusan yang menggunakan perwakilan grafik, i.e., grafik seperti pokok atau model keputusan. Ini biasanya digunakan dalam analisis keputusan dan juga alat yang popular dalam pembelajaran mesin. Pokok keputusan digunakan dalam penyelidikan operasi dan pengurusan operasi.
Ia mempunyai struktur seperti alur di mana setiap simpul dalaman mewakili 'ujian' pada atribut, setiap cabang mewakili hasil ujian, dan setiap simpul daun mewakili label kelas. Laluan dari akar ke daun dikenal sebagai peraturan klasifikasi. Ia terdiri daripada tiga jenis nod:
- Nod keputusan: biasanya diwakili oleh kotak,
- Node peluang: biasanya diwakili oleh bulatan,
- Nod akhir: biasanya diwakili oleh segitiga.
Pokok keputusan mudah difahami dan ditafsirkan. Ia menggunakan model kotak putih. Juga, ia boleh digabungkan dengan teknik keputusan lain.
8. Hutan Rawak
Hutan rawak adalah teknik pembelajaran ensemble yang popular yang beroperasi dengan membina banyak pohon keputusan pada waktu latihan dan menghasilkan kategori yang merupakan mod kategori (klasifikasi) atau ramalan min (regresi) setiap pokok.
Jangka masa algoritma pembelajaran mesin ini cepat, dan dapat berfungsi dengan data yang tidak seimbang dan hilang. Namun, ketika kami menggunakannya untuk regresi, itu tidak dapat meramalkan di luar jangkauan dalam data latihan, dan data tersebut mungkin terlalu sesuai.
9. KERETA
Pohon Klasifikasi dan Regresi (CART) adalah salah satu jenis pokok keputusan. Pohon Keputusan berfungsi sebagai pendekatan partisi rekursif dan CART membahagikan setiap nod input menjadi dua nod anak. Pada setiap peringkat pohon keputusan, algoritma mengenal pasti keadaan - pemboleh ubah dan tahap mana yang akan digunakan untuk membelah nod input menjadi dua nod anak.
Langkah algoritma CART diberikan di bawah:
- Ambil data Input
- Perpecahan Terbaik
- Pembolehubah Terbaik
- Pisahkan data input ke nod kiri dan kanan
- Teruskan langkah 2-4
- Pemangkasan Pokok Keputusan
10. Algoritma Pembelajaran Mesin Apriori

Algoritma Apriori adalah algoritma pengkategorian. Teknik pembelajaran mesin ini digunakan untuk menyusun sejumlah besar data. Ini juga dapat digunakan untuk menindaklanjuti bagaimana hubungan berkembang, dan kategori terbentuk. Algoritma ini adalah kaedah pembelajaran tanpa pengawasan yang menghasilkan peraturan pergaulan dari set data yang diberikan.
Algoritma Pembelajaran Mesin Apriori berfungsi sebagai:
- Sekiranya satu set item berlaku dengan kerap, maka semua subset dari set item juga sering berlaku.
- Sekiranya satu set item jarang berlaku, maka semua superset dari set item juga jarang berlaku.
Algoritma ML ini digunakan dalam pelbagai aplikasi seperti untuk mengesan tindak balas ubat yang merugikan, untuk analisis keranjang pasaran dan aplikasi yang lengkap secara automatik. Ia mudah dilaksanakan.
11. Analisis Komponen Utama (PCA)
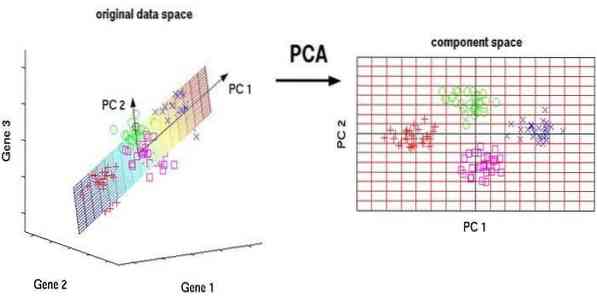
Analisis komponen utama (PCA) adalah algoritma tanpa pengawasan. Ciri-ciri baru adalah ortogonal, itu bermaksud mereka tidak berkorelasi. Sebelum melakukan PCA, anda harus selalu menormalkan set data anda kerana transformasinya bergantung pada skala. Sekiranya tidak, ciri-ciri yang berada pada skala paling ketara akan menguasai komponen utama baru.
PCA adalah teknik serba boleh. Algoritma ini mudah dilakukan dan mudah dilaksanakan. Ia boleh digunakan dalam pemprosesan gambar.
12. CatBoost
CatBoost adalah algoritma pembelajaran mesin sumber terbuka yang berasal dari Yandex. Nama 'CatBoost' berasal dari dua perkataan 'Category' dan 'Boosting.'Ia dapat digabungkan dengan kerangka pembelajaran yang mendalam, i.e., TensorFlow Google dan Apple Core ML. CatBoost boleh berfungsi dengan pelbagai jenis data untuk menyelesaikan beberapa masalah.
13. Dikotomiser Iteratif 3 (ID3)
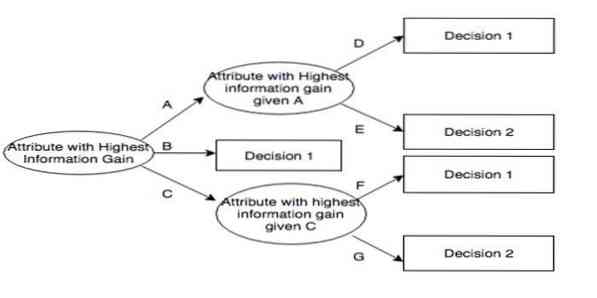
Iterative Dichotomiser 3 (ID3) adalah peraturan algoritma pembelajaran pohon keputusan yang dikemukakan oleh Ross Quinlan yang digunakan untuk membekalkan keputusan keputusan dari set data. Ini adalah pendahulu kepada C4.5 program algoritma dan digunakan dalam domain pembelajaran mesin dan komunikasi proses linguistik.
ID3 mungkin berlebihan pada data latihan. Peraturan algoritma ini lebih sukar digunakan pada data berterusan. Ia tidak menjamin penyelesaian yang optimum.
14. Pengelompokan Hierarki
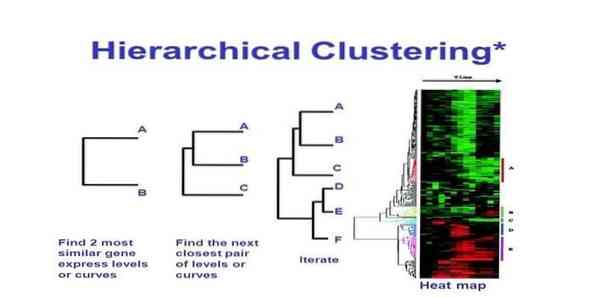
Pengelompokan hierarki adalah kaedah analisis kluster. Dalam pengelompokan hierarki, pohon kluster (dendrogram) dikembangkan untuk menggambarkan data. Dalam pengelompokan hierarki, setiap kumpulan (nod) menghubungkan ke dua atau lebih kumpulan pengganti. Setiap nod di dalam pokok kluster mengandungi data yang serupa. Kumpulan nod pada graf bersebelahan nod serupa yang lain.
Algoritma
Kaedah pembelajaran mesin ini boleh dibahagikan kepada dua model - dari bawah ke atas atau atas ke bawah:
Bottom-up (Pengelompokan Hierarki Agglomeratif, HAC)
- Pada permulaan teknik pembelajaran mesin ini, ambil setiap dokumen sebagai satu kelompok.
- Dalam kluster baru, menggabungkan dua item pada satu masa. Bagaimana gabungan menggabungkan melibatkan perbezaan kalkulator antara setiap pasangan gabungan dan oleh itu sampel alternatif. Terdapat banyak pilihan untuk melakukan ini. Sebahagian daripadanya adalah:
a. Pautan lengkap: Kesamaan pasangan terjauh. Satu batasan adalah bahawa outliers mungkin menyebabkan penggabungan kumpulan dekat lebih lama daripada yang optimum.
b. Tautan tunggal: Kesamaan pasangan terdekat. Ini boleh menyebabkan penggabungan pramatang, walaupun kumpulan tersebut sangat berbeza.
c. Rata-rata kumpulan: persamaan antara kumpulan.
d. Kesamaan Centroid: setiap lelaran menggabungkan kelompok dengan titik pusat yang serupa.
- Sehingga semua item bergabung menjadi satu kluster, proses memasangkan sedang berlangsung.
Atas ke bawah (Penggabungan Divisif)
- Data bermula dengan gabungan kluster.
- Kluster terbahagi kepada dua bahagian yang berbeza, mengikut tahap kesamaan.
- Kluster dibahagikan kepada dua lagi dan lagi sehingga kluster hanya mengandungi satu titik data.
15. Penyebaran Kembali
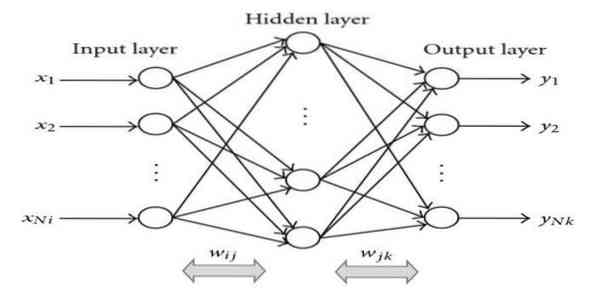
Back-propagation adalah algoritma pembelajaran yang diselia. Algoritma ML ini berasal dari kawasan ANN (Rangkaian Neural Buatan). Rangkaian ini adalah rangkaian feed-forward multilayer. Teknik ini bertujuan untuk merancang fungsi tertentu dengan mengubah bobot dalaman isyarat input untuk menghasilkan isyarat output yang diinginkan. Ia boleh digunakan untuk klasifikasi dan regresi.

Algoritma penyebaran belakang mempunyai beberapa kelebihan, i.e., senang dilaksanakan. Rumus matematik yang digunakan dalam algoritma dapat diterapkan ke rangkaian mana pun. Masa pengiraan dapat dikurangkan jika beratnya kecil.
Algoritma penyebaran balik mempunyai beberapa kelemahan seperti mungkin sensitif terhadap data dan outlier yang bising. Ini adalah pendekatan berasaskan matriks sepenuhnya. Prestasi sebenar algoritma ini bergantung sepenuhnya pada data input. Hasilnya mungkin tidak berangka.
16. AdaBoost
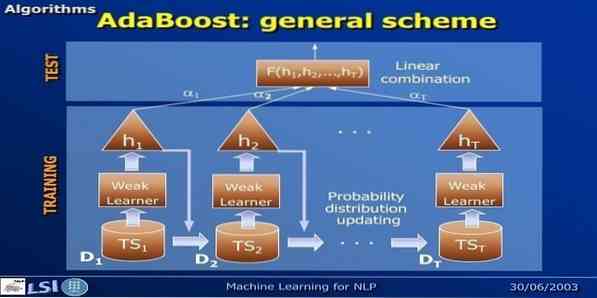
AdaBoost bermaksud Adaptive Boosting, kaedah pembelajaran mesin yang diwakili oleh Yoav Freund dan Robert Schapire. Ini adalah meta-algoritma dan dapat disatukan dengan algoritma pembelajaran lain untuk meningkatkan prestasi mereka. Algoritma ini cepat dan mudah digunakan. Ia berfungsi dengan baik dengan set data yang besar.
17. Pembelajaran Dalam
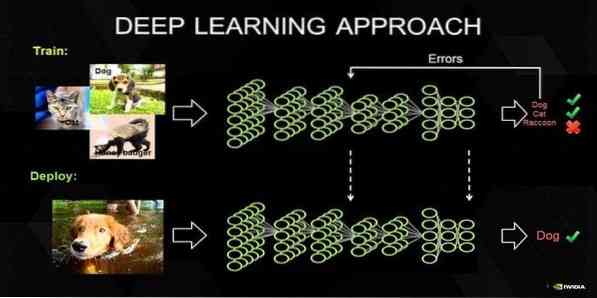
Pembelajaran mendalam adalah satu set teknik yang diilhami oleh mekanisme otak manusia. Dua pembelajaran mendalam utama, i.e., Rangkaian Neural Konvolusi (CNN) dan Rangkaian Neural Berulang (RNN) digunakan dalam klasifikasi teks. Algoritma pembelajaran mendalam seperti Word2Vec atau GloVe juga digunakan untuk mendapatkan gambaran vektor peringkat tinggi dan meningkatkan ketepatan pengelasan yang dilatih dengan algoritma pembelajaran mesin tradisional.
Kaedah pembelajaran mesin ini memerlukan banyak sampel latihan dan bukannya algoritma pembelajaran mesin tradisional, i.e., minimum berjuta-juta contoh berlabel. Sebaliknya, teknik pembelajaran mesin tradisional mencapai ambang yang tepat di mana sahaja menambahkan lebih banyak sampel latihan tidak meningkatkan ketepatan mereka secara keseluruhan. Pengelasan pembelajaran yang mendalam mengungguli hasil yang lebih baik dengan lebih banyak data.
18. Algoritma Peningkatan Gradien

Peningkatan gradien adalah kaedah pembelajaran mesin yang digunakan untuk klasifikasi dan regresi. Ini adalah salah satu kaedah paling berkesan untuk mengembangkan model ramalan. Algoritma peningkatan kecerunan mempunyai tiga elemen:
- Fungsi Kehilangan
- Pelajar Lemah
- Model Aditif
19. Rangkaian Hopfield
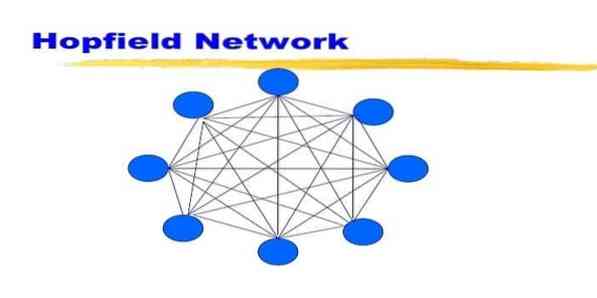
Rangkaian Hopfield adalah sejenis rangkaian saraf tiruan berulang yang diberikan oleh John Hopfield pada tahun 1982. Rangkaian ini bertujuan untuk menyimpan satu atau lebih corak dan mengingat kembali corak lengkap berdasarkan input separa. Dalam rangkaian Hopfield, semua node adalah input dan output dan saling berkaitan sepenuhnya.
20. C4.5

C4.5 adalah pokok keputusan yang dicipta oleh Ross Quinlan. Ini adalah versi peningkatan ID3. Program algoritma ini merangkumi beberapa kes asas:
- Semua sampel dalam senarai tergolong dalam kategori yang serupa. Ini membuat simpul daun untuk pohon keputusan yang mengatakan untuk memutuskan kategori itu.
- Ini membuat simpul keputusan yang lebih tinggi ke atas pokok menggunakan nilai jangkaan kelas.
- Ini membuat simpul keputusan yang lebih tinggi ke atas pokok menggunakan nilai yang diharapkan.
Pemikiran Berakhir
Sangat penting untuk menggunakan algoritma yang betul berdasarkan data dan domain anda untuk membangunkan projek pembelajaran mesin yang cekap. Juga, memahami perbezaan kritikal antara setiap algoritma pembelajaran mesin adalah mustahak untuk ditangani ketika saya memilih yang mana.Seperti, dalam pendekatan pembelajaran mesin, mesin atau peranti telah belajar melalui algoritma pembelajaran. Saya yakin bahawa artikel ini membantu anda memahami algoritma. Sekiranya anda mempunyai cadangan atau pertanyaan, jangan ragu untuk bertanya. Teruskan membaca.


