Reka bentuk bas I / O mewakili arteri komputer dan secara signifikan menentukan berapa banyak dan seberapa cepat data dapat ditukar antara komponen tunggal yang disenaraikan di atas. Kategori teratas dipimpin oleh komponen yang digunakan dalam bidang Pengkomputeran Berprestasi Tinggi (HPC). Pada pertengahan tahun 2020, antara wakil HPC kontemporari adalah Nvidia Tesla dan DGX, Radeon Instinct, dan produk pemecut berasaskan GPU Intel Xeon Phi (lihat [1,2] untuk perbandingan produk).
Memahami NUMA
Akses Tidak Seragam (NUMA) menerangkan seni bina memori bersama yang digunakan dalam sistem pemprosesan kontemporari. NUMA adalah sistem pengkomputeran yang terdiri dari beberapa node tunggal sedemikian rupa sehingga memori agregat dibagi antara semua node: "setiap CPU diberikan memori tempatan sendiri dan dapat mengakses memori dari CPU lain dalam sistem" [12,7].
NUMA adalah sistem pintar yang digunakan untuk menghubungkan beberapa unit pemprosesan pusat (CPU) ke sejumlah memori komputer yang terdapat di komputer. Node NUMA tunggal disambungkan melalui rangkaian berskala (bus I / O) sehingga CPU dapat mengakses memori secara sistematik yang berkaitan dengan nod NUMA lain.
Memori tempatan adalah memori yang digunakan CPU dalam nod NUMA tertentu. Memori asing atau jauh adalah memori yang diambil oleh CPU dari nod NUMA yang lain. Istilah nisbah NUMA menjelaskan nisbah kos mengakses memori asing dengan kos mengakses memori tempatan. Semakin besar nisbahnya, semakin besar kosnya, dan semakin lama masa yang diperlukan untuk mengakses memori.
Namun, ia memerlukan waktu lebih lama daripada ketika CPU mengakses memori tempatan sendiri. Akses memori tempatan adalah kelebihan utama, kerana menggabungkan latensi rendah dengan lebar jalur yang tinggi. Sebaliknya, mengakses memori milik CPU lain mempunyai latensi yang lebih tinggi dan prestasi lebar jalur yang lebih rendah.
Mengimbas Kembali: Evolusi Multiprosesor Memori Bersama
Frank Dennemann [8] menyatakan bahawa seni bina sistem moden tidak benar-benar membenarkan Akses Memori Seragam (UMA), walaupun sistem ini dirancang khusus untuk tujuan tersebut. Secara ringkas, idea pengkomputeran selari adalah untuk mempunyai sekumpulan pemproses yang bekerjasama untuk menghitung tugas yang diberikan, sehingga mempercepat pengiraan berurutan yang klasik.
Seperti yang dijelaskan oleh Frank Dennemann [8], pada awal tahun 1970-an, "perlunya sistem yang dapat melayani beberapa operasi pengguna serentak dan penjanaan data yang berlebihan menjadi arus perdana" dengan pengenalan sistem pangkalan data hubungan. "Walaupun kadar prestasi uniprosesor yang mengagumkan, sistem multiprosesor dilengkapi dengan lebih baik untuk menangani beban kerja ini. Untuk menyediakan sistem yang menjimatkan, ruang alamat memori bersama menjadi tumpuan penyelidikan. Sejak awal, sistem yang menggunakan suis bar palang disarankan, namun dengan kerumitan reka bentuk ini ditingkatkan seiring dengan peningkatan prosesor, yang menjadikan sistem berbasis bus lebih menarik. Pemproses dalam sistem bas [dapat] mengakses seluruh ruang memori dengan menghantar permintaan di dalam bas, cara yang sangat efektif untuk menggunakan memori yang tersedia seoptimum mungkin."
Walau bagaimanapun, sistem komputer berasaskan bas dilengkapi dengan masalah - jumlah lebar jalur yang terhad yang membawa kepada masalah skalabiliti. Semakin banyak CPU yang ditambahkan ke sistem, semakin kurang lebar jalur setiap nod yang ada. Selanjutnya, semakin banyak CPU yang ditambahkan, semakin lama bas, dan semakin tinggi latensi sebagai hasilnya.
Sebilangan besar CPU dibina dalam satah dua dimensi. CPU juga harus ditambahkan pengawal memori terpadu. Penyelesaian mudah untuk mempunyai empat bas memori (atas, bawah, kiri, kanan) ke setiap teras CPU membolehkan lebar jalur tersedia sepenuhnya, tetapi hanya sejauh ini. CPU stagnan dengan empat teras untuk masa yang cukup lama. Menambah jejak di atas dan di bawah membolehkan bas terus ke CPU yang menentang pepenjuru ketika cip menjadi 3D. Menempatkan CPU empat teras pada kad, yang kemudian disambungkan ke bas, adalah langkah logik seterusnya.
Hari ini, setiap pemproses mengandungi banyak teras dengan cache on-chip bersama dan memori off-chip dan mempunyai kos akses memori yang berubah-ubah di pelbagai bahagian memori dalam pelayan.
Meningkatkan kecekapan akses data adalah salah satu tujuan utama reka bentuk CPU kontemporari. Setiap teras CPU dikurniakan dengan cache tahap kecil satu (32 KB) dan cache tahap 2 yang lebih besar (256 KB). Berbagai inti kemudiannya akan berkongsi cache tahap 3 dengan beberapa MB, ukurannya telah bertambah lama dari masa ke masa.
Untuk mengelakkan ketinggalan cache - meminta data yang tidak ada di dalam cache - banyak masa penyelidikan dihabiskan untuk mencari jumlah cache CPU, struktur cache, dan algoritma yang sesuai. Lihat [8] untuk penjelasan yang lebih terperinci mengenai protokol caching snoop [4] dan cache coherency [3,5], serta idea reka bentuk di sebalik NUMA.
Sokongan Perisian untuk NUMA
Terdapat dua langkah pengoptimuman perisian yang dapat meningkatkan prestasi sistem yang menyokong seni bina NUMA - pertalian pemproses dan penempatan data. Seperti yang dijelaskan dalam [19], "afinitas prosesor […] memungkinkan pengikatan dan pengikatan proses atau utas ke satu CPU, atau rentang CPU sehingga proses atau utas hanya dapat dijalankan pada CPU atau CPU yang ditentukan daripada CPU apa pun.Istilah "penempatan data" merujuk pada modifikasi perisian di mana kod dan data disimpan sedekat mungkin dalam memori.
Sistem operasi berkaitan UNIX dan UNIX yang berbeza menyokong NUMA dengan cara berikut (senarai di bawah diambil dari [14]):
- Sokongan Silicon Graphics IRIX untuk seni bina ccNUMA lebih dari 1240 CPU dengan siri pelayan Origin.
- Microsoft Windows 7 dan Windows Server 2008 R2 menambahkan sokongan untuk seni bina NUMA lebih daripada 64 teras logik.
- Versi 2.5 kernel Linux sudah mengandungi sokongan asas NUMA, yang semakin diperbaiki dalam pelepasan kernel berikutnya. Versi 3.8 kernel Linux membawa asas NUMA baru yang memungkinkan pengembangan dasar NUMA yang lebih cekap dalam pelepasan kernel kemudian [13]. Versi 3.13 kernel Linux membawa banyak dasar yang bertujuan untuk meletakkan proses yang hampir dengan ingatannya, bersama dengan pengendalian kes, seperti halaman memori dikongsi antara proses, atau penggunaan halaman besar yang telus; tetapan kawalan sistem baru membolehkan pengimbangan NUMA diaktifkan atau dinonaktifkan, serta konfigurasi pelbagai parameter pengimbangan memori NUMA [15].
- Kedua-dua Oracle dan OpenSolaris model seni bina NUMA dengan pengenalan kumpulan logik.
- FreeBSD menambahkan konfigurasi dasar dan pertalian NUMA awal dalam versi 11.0.
Dalam buku "Sains Komputer dan Teknologi, Prosiding Persidangan Antarabangsa (CST2016)" Ning Cai menunjukkan bahawa kajian seni bina NUMA tertumpu terutamanya pada persekitaran pengkomputeran kelas atas dan mencadangkan Radix Partitioning (NaRP) yang menyedari NUMA, yang mengoptimumkan prestasi cache bersama dalam node NUMA untuk mempercepat aplikasi risikan perniagaan. Oleh itu, NUMA mewakili jalan tengah antara sistem memori bersama (SMP) dengan beberapa pemproses [6].
NUMA dan Linux
Seperti yang dinyatakan di atas, kernel Linux telah menyokong NUMA sejak versi 2.5. Kedua-dua Debian GNU / Linux dan Ubuntu menawarkan sokongan NUMA untuk pengoptimuman proses dengan dua pakej perisian numactl [16] dan numad [17]. Dengan bantuan perintah numactl, anda boleh menyenaraikan inventori NUMA node yang ada di sistem anda [18]:
# numactl - perkakasantersedia: 2 nod (0-1)
nod 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
ukuran simpul 0: 8157 MB
simpul 0 percuma: 88 MB
nod 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
saiz nod 1: 8191 MB
simpul 1 percuma: 5176 MB
jarak nod:
nod 0 1
0: 10 20
1: 20 10
NumaTop adalah alat berguna yang dikembangkan oleh Intel untuk memantau lokasi memori runtime dan menganalisis proses dalam sistem NUMA [10,11]. Alat ini dapat mengenal pasti potensi kemacetan prestasi yang berkaitan dengan NUMA dan dengan itu membantu untuk mengimbangi semula peruntukan memori / CPU untuk memaksimumkan potensi sistem NUMA. Lihat [9] untuk keterangan yang lebih terperinci.
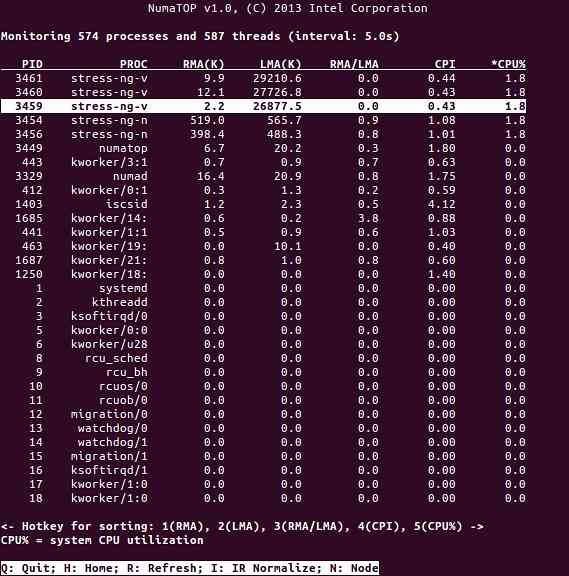
Senario Penggunaan
Komputer yang menyokong teknologi NUMA membolehkan semua CPU mengakses keseluruhan memori secara langsung - CPU melihatnya sebagai ruang alamat linier tunggal. Ini membawa kepada penggunaan skema pengalamatan 64-bit yang lebih cekap, menghasilkan pergerakan data yang lebih cepat, kurang replikasi data, dan pengaturcaraan yang lebih mudah.
Sistem NUMA cukup menarik untuk aplikasi sisi pelayan, seperti sistem perlombongan data dan sokongan keputusan. Tambahan pula, menulis aplikasi untuk permainan dan perisian berprestasi tinggi menjadi lebih mudah dengan seni bina ini.
Kesimpulannya
Kesimpulannya, seni bina NUMA menangani skalabiliti, yang merupakan salah satu faedah utamanya. Dalam CPU NUMA, satu node akan mempunyai lebar jalur yang lebih tinggi atau latensi yang lebih rendah untuk mengakses memori pada node yang sama (e.g., CPU tempatan meminta akses memori pada masa yang sama dengan akses jauh; keutamaan adalah pada CPU tempatan). Ini akan meningkatkan daya ingatan secara dramatik jika data dilokalisasikan ke proses tertentu (dan dengan itu pemproses). Kelemahannya adalah kos pemindahan data yang lebih tinggi dari satu pemproses ke pemproses yang lain. Selagi kes ini tidak berlaku terlalu kerap, sistem NUMA akan mengungguli sistem dengan seni bina yang lebih tradisional.
Pautan dan Rujukan
- Bandingkan NVIDIA Tesla vs. Naluri Radeon, https: // www.pusat pemusatan.com / produk / perbandingan / nvidia-tesla_vs_radeon-insting
- Bandingkan NVIDIA DGX-1 vs. Naluri Radeon, https: // www.pusat pemusatan.com / produk / perbandingan / nvidia-dgx-1_vs_radeon-instinct
- Koherensi cache, Wikipedia, https: // en.wikipedia.org / wiki / Cache_coherence
- Pengintipan bas, Wikipedia, https: // en.wikipedia.org / wiki / Bus_snooping
- Protokol koherensi cache dalam sistem multiprosesor, Geeks untuk geeks, https: // www.geeksforgeeks.org / cache-koherence-protokol-dalam-multiprosesor-sistem /
- Sains dan teknologi komputer - Prosiding Persidangan Antarabangsa (CST2016), Ning Cai (Ed., World Scientific Publishing Co Pte Ltd, ISBN: 9789813146419
- Daniel P. Bovet dan Marco Cesati: Memahami seni bina NUMA dalam Memahami Kernel Linux, edisi ke-3, O'Reilly, https: // www.oreilly.com / perpustakaan / paparan / pemahaman-the-linux / 0596005652 /
- Frank Dennemann: NUMA Deep Dive Bahagian 1: Dari UMA hingga NUMA, https: // frankdenneman.nl / 2016/07/07 / numa-deep-dive-part-1-uma-numa /
- Colin Ian King: NumaTop: Alat pemantauan sistem NUMA, http: // smackerelofopinion.blogspot.com / 2015/09 / alat pemantauan-sistem-numa-numa.html
- Numatop, https: // github.com / intel / numatop
- Pakej numatop untuk pakej Debian GNU / Linux, https: //.debian.org / buster / numatop
- Jonathan Kehayias: Memahami Akses / Senibina Memori Tidak Seragam (NUMA), https: // www.sqlskills.com / blog / jonathan / pemahaman-tidak seragam-memori-aksesarkibina-numa /
- Berita Kernel Linux untuk Kernel 3.8, https: // kernelnewbies.org / Linux_3.8
- Akses memori tidak seragam (NUMA), Wikipedia, https: // en.wikipedia.org / wiki / Tidak seragam_memory_access
- Dokumentasi Pengurusan Memori Linux, NUMA, https: // www.kernel.org / doc / html / terkini / vm / numa.html
- Pakej numactl untuk pakej Debian GNU / Linux, https: //.debian.org / sid / admin / numactl
- Numad pakej untuk pakej Debian GNU / Linux, https: //.debian.org / buster / numad
- Cara mencari jika konfigurasi NUMA diaktifkan atau dilumpuhkan?, https: // www.thegeekdiary.com / centos-rhel-bagaimana-untuk-mencari-jika-numa-konfigurasi-adalah-diaktifkan-atau-dilumpuhkan /
- Perkaitan pemproses, Wikipedia, https: // en.wikipedia.org / wiki / Processor_affinity
Terima kasih
Penulis ingin mengucapkan terima kasih kepada Gerold Rupprecht atas sokongannya semasa menyiapkan artikel ini.
Mengenai Pengarang
Plaxedes Nehanda adalah seorang yang serba boleh, serba boleh, memandu sendiri yang memakai banyak topi, di antaranya, perancang acara, pembantu maya, penyampai, dan juga penyelidik yang gemar, yang berpusat di Johannesburg, Afrika Selatan.
Putera K. Nehanda adalah Jurutera Instrumentasi dan Kawalan (Metrologi) di Paeflow Metering di Harare, Zimbabwe.
Frank Hofmann bekerja di jalan raya - lebih baik dari Berlin (Jerman), Geneva (Switzerland), dan Cape Town (Afrika Selatan) - sebagai pembangun, pelatih, dan pengarang untuk majalah seperti Linux-User dan Linux Magazine. Dia juga merupakan pengarang bersama buku pengurusan pakej Debian (http: // www.dpmb.org).


