Dalam pelajaran ini, kita akan melihat apa itu Apache Kafka dan bagaimana ia berfungsi bersama dengan beberapa kes penggunaan yang paling biasa. Apache Kafka pada mulanya dikembangkan di LinkedIn pada tahun 2010 dan berpindah menjadi projek Apache peringkat tertinggi pada tahun 2012. Ia mempunyai tiga komponen utama:
- Penerbit-Pelanggan: Komponen ini bertanggungjawab untuk mengurus dan menyampaikan data dengan cekap di seluruh Kafka Nodes dan aplikasi pengguna yang banyak (seperti harfiah).
- Sambungkan API: Connect API adalah ciri yang paling berguna untuk Kafka dan membolehkan penyatuan Kafka dengan banyak sumber data luaran dan sink data.
- Aliran Kafka: Dengan menggunakan Aliran Kafka, kami dapat mempertimbangkan memproses data masuk dalam skala dalam waktu hampir nyata.
Kami akan mengkaji lebih banyak konsep Kafka di bahagian yang akan datang. Mari maju.
Konsep Apache Kafka
Sebelum kita menggali lebih mendalam, kita perlu meneliti beberapa konsep dalam Apache Kafka. Inilah syarat-syarat yang harus kita ketahui, secara ringkas:
-
- Penerbit: Ini adalah aplikasi yang mengirim pesan ke Kafka
- Pengguna: Ini adalah aplikasi yang menggunakan data dari Kafka
- Mesej: Data yang dihantar oleh aplikasi Producer ke aplikasi Pengguna melalui Kafka
- Sambungan: Kafka mewujudkan TCP Connection antara kluster Kafka dan aplikasi
- Topik: Topik adalah kategori kepada siapa data yang dikirim ditandai dan dikirimkan ke aplikasi pengguna yang berminat
- Partisi topik: Kerana satu topik dapat memperoleh banyak data sekaligus, untuk memastikan Kafka dapat ditingkatkan secara mendatar, setiap topik dibahagikan kepada partisi dan setiap partisi dapat hidup di mana-mana mesin nod kluster. Mari kita cuba membentangkannya:
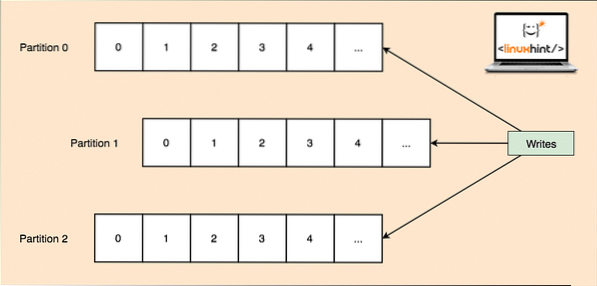
Pembahagian Topik
- Replika: Seperti yang kita pelajari di atas bahawa topik dibahagikan kepada partisi, setiap catatan mesej ditiru pada beberapa nod kluster untuk mengekalkan urutan dan data setiap catatan sekiranya salah satu node mati.
- Kumpulan Pengguna: Pelbagai pengguna yang berminat dengan topik yang sama boleh disimpan dalam kumpulan yang disebut sebagai Kumpulan Pengguna
- Mengimbangi: Kafka dapat diskalakan kerana pengguna yang sebenarnya menyimpan mesej mana yang diambil oleh mereka terakhir sebagai nilai 'offset'. Ini bermaksud bahawa untuk topik yang sama, ofset Consumer A mungkin mempunyai nilai 5 yang bermaksud bahawa ia perlu memproses paket keenam seterusnya dan untuk Consumer B, nilai offset mungkin 7 yang bermaksud perlu memproses paket kelapan berikutnya. Ini sepenuhnya menghilangkan kebergantungan pada topik itu sendiri untuk menyimpan meta-data ini yang berkaitan dengan setiap pengguna.
- Node: Node adalah mesin pelayan tunggal dalam kluster Apache Kafka.
- Kluster: Kluster adalah sekumpulan nod i.e., sekumpulan pelayan.
Konsep untuk Topik, Partisi Topik dan ofset juga dapat dijelaskan dengan gambaran:
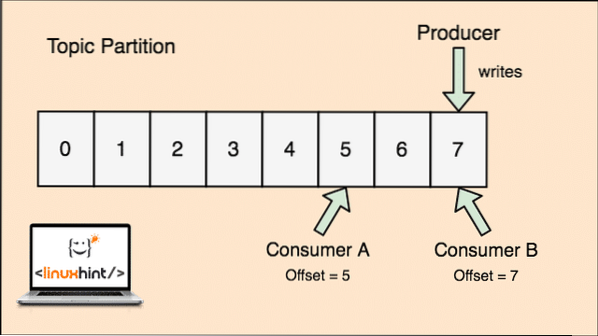
Bahagian topik dan Pengimbangan pengguna di Apache Kafka
Apache Kafka sebagai sistem pesanan Publish-subscribe
Dengan Kafka, aplikasi Producer menerbitkan mesej yang tiba di Kafka Node dan tidak terus kepada Pengguna. Dari Kafka Node ini, mesej digunakan oleh aplikasi Pengguna.
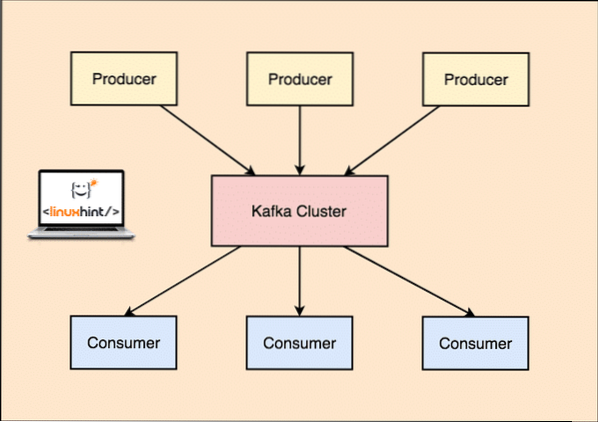
Pengeluar dan Pengguna Kafka
Oleh kerana satu topik dapat memperoleh banyak data sekaligus, untuk memastikan Kafka dapat ditingkatkan secara mendatar, setiap topik dibahagikan kepada partition dan setiap partisi boleh hidup di mana-mana mesin nod kluster.
Sekali lagi, Kafka Broker tidak menyimpan rekod pengguna mana yang telah menggunakan berapa banyak paket data. Ia adalah tanggungjawab pengguna untuk memantau data yang telah digunakannya. Oleh kerana Kafka tidak memantau pengakuan dan pesanan setiap aplikasi pengguna, ia dapat menguruskan lebih banyak pengguna dengan kesan yang tidak dapat diabaikan pada throughput. Dalam pengeluaran, banyak aplikasi bahkan mengikuti pola konsumen batch, yang bermaksud bahawa pengguna menggunakan semua pesan dalam antrian pada selang waktu yang tetap.
Pemasangan
Untuk mula menggunakan Apache Kafka, ia mesti dipasang pada mesin. Untuk melakukan ini, baca Pasang Apache Kafka di Ubuntu.
Kes Penggunaan: Penjejakan Penggunaan Laman Web
Kafka adalah alat yang sangat baik untuk digunakan ketika kita perlu mengesan aktiviti di laman web. Data penjejakan merangkumi dan tidak terhad pada paparan halaman, carian, muat naik atau tindakan lain yang mungkin dilakukan oleh pengguna. Ketika pengguna berada di laman web, pengguna mungkin melakukan sejumlah tindakan ketika dia melayari laman web.
Sebagai contoh, apabila pengguna baru mendaftar di laman web, aktiviti tersebut mungkin akan dilacak dalam urutan apa pengguna baru meneroka ciri-ciri laman web, jika pengguna menetapkan profil mereka seperti yang diperlukan atau lebih suka langsung menggunakan ciri-ciri laman web. Setiap kali pengguna mengklik butang, metadata untuk butang tersebut dikumpulkan dalam paket data dan dikirimkan ke kluster Kafka dari mana perkhidmatan analisis untuk aplikasi dapat mengumpulkan data ini dan menghasilkan wawasan berguna mengenai data yang berkaitan. Sekiranya kita ingin membahagikan tugas menjadi beberapa langkah, berikut adalah bagaimana prosesnya akan kelihatan seperti:
- Seorang pengguna mendaftar di laman web dan memasuki papan pemuka. Pengguna cuba mengakses ciri secara langsung dengan berinteraksi dengan butang.
- Aplikasi web membina mesej dengan metadata ini ke partisi topik topik "klik".
- Mesej ditambahkan ke log komit dan offset meningkat
- Pengguna kini boleh menarik mesej dari Kafka Broker dan menunjukkan penggunaan laman web secara real-time dan menunjukkan data masa lalu jika ia menetapkan semula offsetnya ke nilai masa lalu yang mungkin
Guna Kes: Antrian Mesej
Apache Kafka adalah alat yang sangat baik yang boleh bertindak sebagai pengganti alat broker mesej seperti RabbitMQ. Pemesejan tak segerak membantu mencabut aplikasi dan membuat sistem yang sangat berskala.
Sama seperti konsep perkhidmatan mikro, alih-alih membangun satu aplikasi besar, kita dapat membagi aplikasi menjadi beberapa bahagian dan setiap bahagian mempunyai tanggungjawab yang sangat spesifik. Dengan cara ini, bahagian yang berbeza dapat ditulis dalam bahasa pengaturcaraan yang sepenuhnya bebas! Kafka mempunyai sistem partisi, replikasi, dan toleransi kesalahan yang ada di dalamnya yang menjadikannya baik sebagai sistem broker pesanan berskala besar.
Baru-baru ini, Kafka juga dilihat sebagai penyelesaian pengumpulan log yang sangat baik yang dapat menguruskan broker pelayan pengumpulan fail log dan menyediakan fail-fail ini ke sistem pusat. Dengan Kafka, adalah mungkin untuk menjana sebarang acara yang anda ingin tahu mengenai bahagian lain dari aplikasi anda.
Menggunakan Kafka di LinkedIn
Sangat menarik untuk diperhatikan bahawa Apache Kafka sebelumnya dilihat dan digunakan sebagai cara bagaimana saluran data dapat dibuat konsisten dan melalui mana data dimasukkan ke Hadoop. Kafka berfungsi dengan baik ketika terdapat banyak sumber dan destinasi data dan menyediakan proses saluran paip yang terpisah untuk setiap kombinasi sumber dan destinasi tidak mungkin. Arkitek Kafka LinkedIn, Jay Kreps menerangkan masalah biasa ini dalam catatan blog:
Penglibatan saya sendiri dalam ini bermula sekitar tahun 2008 setelah kami menghantar kedai nilai kunci kami. Projek saya yang seterusnya adalah untuk mencuba penyediaan Hadoop yang berfungsi, dan memindahkan beberapa proses cadangan kami ke sana. Mempunyai sedikit pengalaman dalam bidang ini, secara semula jadi kami menganggarkan beberapa minggu untuk mendapatkan data masuk dan keluar, dan sisa masa kami untuk melaksanakan algoritma ramalan. Maka bermulalah slogan yang panjang.
Apache Kafka dan Flume
Sekiranya anda memilih untuk membandingkan kedua-duanya berdasarkan fungsinya, anda akan menemui banyak ciri umum. Berikut adalah beberapa daripadanya:
- Dianjurkan untuk menggunakan Kafka ketika Anda memiliki banyak aplikasi yang menggunakan data dan bukannya Flume, yang dibuat khusus untuk disatukan dengan Hadoop dan hanya dapat digunakan untuk memasukkan data ke HDFS dan HBase. Flume dioptimumkan untuk operasi HDFS.
- Dengan Kafka, adalah kelemahan untuk membuat kod aplikasi pengeluar dan pengguna sedangkan di Flume, ia mempunyai banyak sumber dan sinki bawaan. Ini bermaksud bahawa jika keperluan yang ada sesuai dengan ciri Flume, anda disarankan untuk menggunakan Flume itu sendiri untuk menjimatkan masa.
- Flume boleh menggunakan data dalam penerbangan dengan bantuan pemintas. Ini penting bagi penyamaran dan penapisan data sedangkan Kafka memerlukan sistem pemprosesan aliran luaran.
- Ada kemungkinan bagi Kafka untuk menggunakan Flume sebagai pengguna ketika kita perlu memasukkan data ke HDFS dan HBase. Ini bermakna Kafka dan Flume bergabung dengan sangat baik.
- Kakfa dan Flume dapat menjamin kehilangan data sifar dengan konfigurasi yang betul yang mudah dicapai juga. Namun, untuk menunjukkan, Flume tidak meniru peristiwa yang bermaksud bahawa jika salah satu node Flume gagal, kita akan kehilangan akses acara sehingga cakera pulih
Kesimpulannya
Dalam pelajaran ini, kami melihat banyak konsep mengenai Apache Kafka. Baca lebih banyak catatan berdasarkan Kafka di sini.


