Data besar adalah data dalam urutan terabyte atau petabyte dan seterusnya, yang terdiri daripada perlombongan, analisis, dan pemodelan ramalan set data besar. Pertumbuhan pesat perkembangan maklumat dan teknologi telah memberikan peluang unik bagi individu dan perusahaan di seluruh dunia untuk memperoleh keuntungan dan mengembangkan keupayaan baru untuk mentakrifkan semula model perniagaan tradisional menggunakan analisis skala besar.
Artikel ini memberikan gambaran mengenai lima platform data sumber terbuka yang paling popular. Inilah senarai kami:
Apache Hadoop
Apache Hadoop adalah platform perisian sumber terbuka yang memproses set data yang sangat besar dalam persekitaran yang diedarkan berkenaan dengan penyimpanan dan kuasa komputasi, dan terutamanya dibina berdasarkan perkakasan komoditi kos rendah.
Apache Hadoop direka untuk meningkatkan dengan mudah dari beberapa hingga ribuan pelayan. Ini membantu anda memproses data yang disimpan secara tempatan dalam penyediaan pemprosesan selari keseluruhan. Salah satu kelebihan Hadoop adalah menangani kegagalan pada peringkat perisian. Gambar berikut menggambarkan keseluruhan seni bina Ekosistem Hadoop dan di mana kerangka kerja yang berbeza berada di dalamnya:
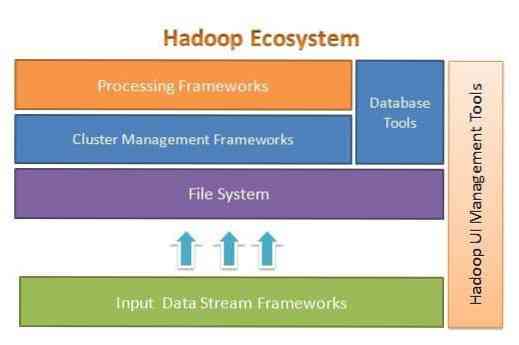
Apache Hadoop menyediakan kerangka untuk lapisan sistem file, lapisan pengelolaan kluster, dan lapisan pemprosesan. Ini memberikan pilihan untuk projek dan kerangka kerja lain untuk datang dan bekerja di samping Hadoop Ecosystem dan mengembangkan kerangka mereka sendiri untuk mana-mana lapisan yang terdapat dalam sistem.
Apache Hadoop terdiri daripada empat modul utama. Modul-modul ini adalah Hadoop Distused File System (lapisan sistem fail), Hadoop MapReduce (yang berfungsi dengan pengurusan kluster dan lapisan pemprosesan), Namun Satu Sumber Perunding Lain (YARN, lapisan pengurusan kluster), dan Hadoop Common.
Pencarian elastik
Elasticsearch adalah mesin carian dan analisis berasaskan teks penuh. Ini adalah sistem yang sangat terukur dan diedarkan, yang dirancang khusus untuk berfungsi dengan cekap dan cepat dengan sistem data besar, di mana salah satu kes penggunaan utamanya adalah analisis log. Ia mampu melakukan carian lanjutan dan kompleks, dan pemprosesan hampir masa nyata untuk analisis lanjutan dan kecerdasan operasi.
Elasticsearch ditulis dalam Java dan berdasarkan Apache Lucene. Dilancarkan pada tahun 2010 dan dengan cepat mendapat populariti kerana struktur data yang fleksibel, seni bina yang berskala, dan masa respons yang sangat cepat. Elasticsearch didasarkan pada dokumen JSON dengan struktur bebas skema, menjadikan adopsi mudah dan bebas kerumitan. Ini adalah salah satu enjin carian teratas kelas perusahaan. Anda boleh menulis pelanggannya dalam bahasa pengaturcaraan; Elasticsearch secara rasmi bekerja dengan Java, .NET, PHP, Python, Perl, dan sebagainya.
Elasticsearch terutamanya berinteraksi menggunakan REST API. Ia memperoleh data dalam bentuk dokumen JSON dengan semua parameter yang diperlukan, dan memberikan responsnya dengan cara yang serupa.
MongoDB
MongoDB adalah pangkalan data NoSQL berdasarkan model data penyimpanan dokumen. Di MongoDB semuanya ada koleksi atau dokumen. Untuk memahami terminologi MongoDB, pengumpulan adalah kata alternatif untuk jadual, sedangkan dokumen adalah kata alternatif untuk baris.
MongoDB adalah pangkalan data sumber terbuka, berorientasikan dokumen, dan lintas platform. Ia ditulis terutamanya dalam C++. Ia juga merupakan pangkalan data NoSQL terkemuka yang memberikan prestasi tinggi, ketersediaan tinggi, dan skalabilitas yang mudah. MongoDB menggunakan dokumen seperti JSON dengan skema dan memberikan sokongan pertanyaan yang kaya. Beberapa ciri utama termasuk pengindeksan, replikasi, pengimbangan beban, agregasi, dan penyimpanan fail.
Cassandra
Cassandra adalah Projek Apache sumber terbuka yang direka untuk pengurusan pangkalan data NoSQL. Baris Cassandra disusun ke dalam jadual dan diindeks oleh kunci. Ia menggunakan enjin penyimpanan berasaskan log tambahan sahaja. Data di Cassandra diedarkan di beberapa nod tanpa master, tanpa satu titik kegagalan. Ia adalah projek Apache tingkat atas, dan pengembangannya saat ini diawasi oleh Apache Software Foundation (ASF).
Cassandra direka untuk menyelesaikan masalah yang berkaitan dengan operasi pada skala besar (web). Memandangkan seni bina tanpa kendali Cassandra, ia dapat terus melakukan operasi walaupun sejumlah kecil kegagalan perkakasan (walaupun signifikan). Cassandra berjalan di pelbagai nod di beberapa pusat data. Ia mereplikasi data di pusat data ini untuk mengelakkan kegagalan atau waktu henti. Ini menjadikannya sistem toleransi kesalahan.
Cassandra menggunakan bahasa pengaturcaraannya sendiri untuk mengakses data di simpulnya. Ia dipanggil Cassandra Query Language atau CQL. Ia serupa dengan SQL, yang terutama digunakan oleh Pangkalan Data Relasional. CQL dapat digunakan dengan menjalankan aplikasinya sendiri yang disebut cqlsh. Cassandra juga menyediakan banyak antara muka integrasi untuk pelbagai bahasa pengaturcaraan untuk membina aplikasi menggunakan Cassandra. API integrasinya menyokong Java, C ++, Python, dan lain-lain.
Apache HBase
HBase adalah Projek Apache lain yang dirancang untuk menguruskan penyimpanan data NoSQL. Ia direka untuk menggunakan ciri-ciri Hadoop Ecosystem, termasuk kebolehpercayaan, toleransi kesalahan, dan sebagainya. Ia menggunakan HDFS sebagai sistem fail untuk tujuan penyimpanan. Terdapat beberapa model data yang digunakan oleh NoSQL dan Apache HBase tergolong dalam model data berorientasikan lajur. HBase pada mulanya berdasarkan Google Big Table, yang juga berkaitan dengan model berorientasikan lajur untuk data tidak berstruktur.
HBase menyimpan semuanya dalam bentuk pasangan nilai-kunci. Perkara penting yang perlu diberi perhatian ialah di HBase, kunci dan nilai adalah dalam bentuk bait. Oleh itu, untuk menyimpan maklumat dalam HBase, anda harus menukar maklumat menjadi bait. (Dengan kata lain, APInya tidak menerima apa-apa selain array byte.) Hati-hati dengan HBase, kerana semasa anda menyimpan data, anda harus ingat jenis asalnya. Data yang pada awalnya rentetan akan dikembalikan sebagai tatasusunan bait jika diingat dengan tidak betul. Akibatnya, ia akan membuat bug pada aplikasi anda dan merosakkan aplikasi anda.
Semoga anda menikmati artikel ini. Sekiranya anda mencari arkitek dan merancang aplikasi intensif data, maka anda boleh meneroka Anuj Kumar Aplikasi Intensif Data Senibina. Ini buku adalah pintu masuk anda untuk membangun sistem intensif data pintar dengan memasukkan prinsip, corak, dan teknik seni bina intensif data inti secara langsung ke dalam seni bina aplikasi anda.

