Untuk memahami konsep carian teks penuh, anda harus mengingati pengetahuan carian corak melalui kata kunci LIKE. Oleh itu, mari kita anggap jadual 'orang' dalam pangkalan data 'ujian' dengan catatan berikut di dalamnya.
>> PILIH * DARI orang;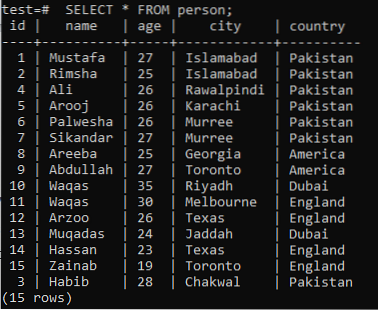
Katakan anda mahu mengambil rekod jadual ini, di mana lajur 'name' mempunyai watak 'i' dalam salah satu nilainya. Cuba pertanyaan PILIH di bawah sambil menggunakan klausa LIKE di shell-command. Dari output di bawah, anda dapat melihat bahawa kami hanya mempunyai 5 rekod untuk watak khas ini 'i' di lajur 'nama'.
>> PILIH * DARI orang DI MANA nama SEPERTI '% i%';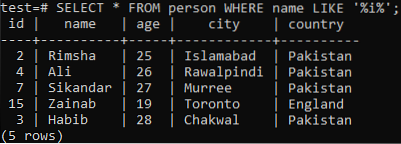
Penggunaan Tvsector:
Kadang-kadang tidak ada gunanya menggunakan LIKE Keyword untuk melakukan pencarian corak cepat, walaupun kata itu ada. Mungkin anda akan mempertimbangkan untuk menggunakan ungkapan standard, dan walaupun ini adalah alternatif yang dapat dilaksanakan, ungkapan biasa kuat dan lambat. Mempunyai vektor prosedur untuk keseluruhan perkataan dalam teks, penerangan vernakular kata-kata itu, adalah cara yang jauh lebih berkesan untuk menangani masalah ini. Konsep carian teks lengkap dan jenis data tsvector diciptakan untuk bertindak balas terhadapnya. Terdapat dua kaedah dalam PostgreSQL yang melakukan apa yang kita mahukan:
- Ke_tvsector: Digunakan untuk membuat senarai token (ts bermaksud "carian teks").
- Ke_tanya: Digunakan untuk mencari vektor mengenai kejadian istilah atau frasa tertentu.
Contoh 01:
Mari kita mulakan dengan gambaran ringkas membuat vektor. Anggaplah anda ingin membuat vektor untuk tali: “Beberapa orang mempunyai rambut coklat kerinting dengan cara menyikat yang betul.". Oleh itu, anda harus menulis fungsi to_tvsector () bersama dengan kalimat ini dalam kurungan pertanyaan SELECT seperti yang dilampirkan di bawah. Dari output di bawah, anda dapat melihatnya akan menghasilkan vektor rujukan (kedudukan fail) untuk setiap token, dan juga di mana istilah dengan sedikit konteks, seperti artikel (the) dan konjungsi (dan, atau), sengaja diabaikan.
>> PILIH ke_tsvector ('Beberapa orang mempunyai rambut coklat kerinting melalui penyikat yang betul');
Contoh 02:
Andaikan anda mempunyai dua dokumen dengan beberapa data di kedua-duanya. Untuk menyimpan data ini, sekarang kita akan menggunakan contoh sebenar menghasilkan token. Andaikan anda telah membuat jadual 'Data' dalam pangkalan data anda 'ujian' dengan beberapa lajur di dalamnya menggunakan pertanyaan CREATE TABLE di bawah ini. Jangan lupa untuk membuat ruangan jenis TVSECTOR bernama 'token' di dalamnya. Dari keluaran di bawah, anda dapat melihat jadual yang telah dibuat.
>> BUAT TABLE Data (Id SERIAL PRIMARY KEY, info TEXT, token TSVECTOR);
Sekarang, kita perlu menambahkan keseluruhan data kedua-dua dokumen dalam jadual ini. Oleh itu, cubalah arahan INSERT di bawah pada baris arahan anda untuk melakukannya. Akhirnya, rekod dari kedua-dua dokumen berjaya ditambahkan ke dalam jadual 'Data'.
>> INSERT INTO Data (info) NILAI ('Dua kesalahan tidak pernah dapat menjadikannya betul.'), (' Dia adalah orang yang boleh bermain bola sepak.'), (' Bolehkah saya berperanan dalam hal ini?'), (' Rasa sakit di dalam diri seseorang tidak dapat difahami '), (' Bawakan buah persik dalam hidup anda);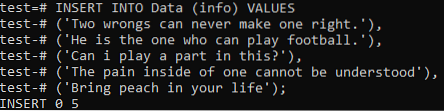
Sekarang anda harus menjajah ruang token kedua-dua dokumen dengan vektornya yang spesifik. Pada akhirnya, pertanyaan UPDATE yang sederhana akan mengisi ruangan token dengan vektor yang sesuai untuk setiap fail. Oleh itu, anda harus melaksanakan pertanyaan di bawah yang dinyatakan di shell-command untuk melakukannya. Hasilnya menunjukkan bahawa kemas kini akhirnya dibuat.
>> UPDATE Data f1 SET token = to_tsvector (f1.info) DARI Data f2;
Sekarang kita sudah mempunyai semuanya, mari kembali ke ilustrasi "can one" dengan imbasan. Untuk_tanya dengan operator AND, seperti yang dikatakan sebelumnya, tidak ada perbezaan antara lokasi fail dalam.
>> PILIH Id, maklumat DARI Data DI MANA token @@ to_tsquery ('can & one');
Contoh 04:
Untuk mencari kata-kata yang "bersebelahan" antara satu sama lain, kami akan mencuba pertanyaan yang sama dengan '<->'pengendali. Perubahan ditunjukkan dalam output di bawah.
>> SELECT Id, info DARI Data DI MANA token @@ to_tsquery ('can <-> satu ');
Berikut adalah contoh kata tidak langsung di sebelah yang lain.
>> PILIH Id, maklumat DARI Data DI MANA token @@ to_tsquery ('satu <-> sakit ');
Contoh 05:
Kami akan mencari kata-kata yang tidak bersebelahan dengan menggunakan nombor di operator jarak untuk merujuk jarak. Kedekatan antara 'bawa' dan 'hidup adalah 4 perkataan selain daripada gambar yang dipaparkan.
>> PILIH * DARI Data DI MANA token @@ to_tsquery ('bawa <4> kehidupan ');
Untuk memeriksa jarak antara perkataan hampir 5 perkataan dilampirkan di bawah.
>> PILIH * DARI Data DI MANA token @@ to_tsquery ('salah <5> betul ');
Kesimpulan:
Akhirnya, anda telah melakukan semua contoh carian teks penuh yang mudah dan rumit menggunakan operator dan fungsi To_tvsector dan to_tsquery.


