Mencari dan memilih elemen dari laman web adalah kunci untuk mengikis web dengan Selenium. Untuk mencari dan memilih elemen dari laman web, anda boleh menggunakan pemilih XPath di Selenium.
Dalam artikel ini, saya akan menunjukkan kepada anda cara mencari dan memilih elemen dari laman web menggunakan pemilih XPath di Selenium dengan perpustakaan Selenium python. Oleh itu, mari kita mulakan.
Prasyarat:
Untuk mencuba perintah dan contoh artikel ini, anda mesti ada,
- Sebaran Linux (sebaiknya Ubuntu) dipasang di komputer anda.
- Python 3 dipasang pada komputer anda.
- PIP 3 dipasang pada komputer anda.
- Python virtualenv pakej yang dipasang di komputer anda.
- Penyemak imbas web Mozilla Firefox atau Google Chrome yang dipasang di komputer anda.
- Mesti tahu cara memasang Pemacu Firefox Gecko atau Pemandu Web Chrome.
Untuk memenuhi syarat 4, 5, dan 6, baca artikel saya Pengenalan Selenium di Python 3. Anda boleh menemui banyak artikel mengenai topik lain di LinuxHint.com. Pastikan anda memeriksanya jika anda memerlukan bantuan.
Menyiapkan Direktori Projek:
Untuk memastikan semuanya teratur, buat direktori projek baru selenium-xpath / seperti berikut:
$ mkdir -pv selenium-xpath / pemacu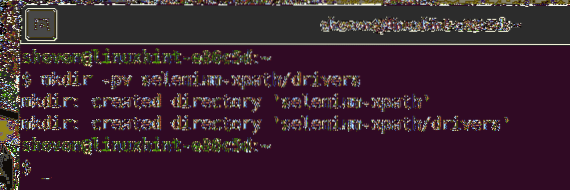
Navigasi ke selenium-xpath / direktori projek seperti berikut:
$ cd selenium-xpath /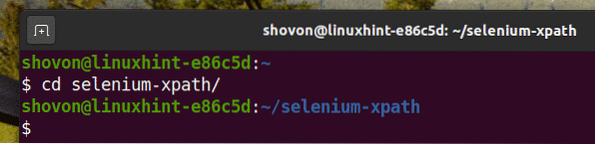
Buat persekitaran maya Python dalam direktori projek seperti berikut:
$ virtualenv .venv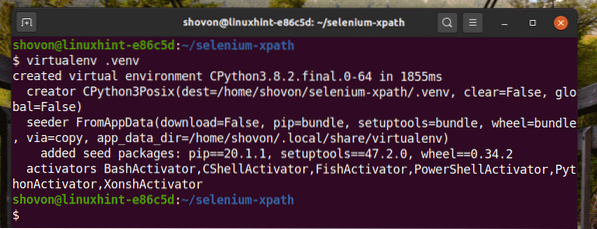
Aktifkan persekitaran maya seperti berikut:
sumber $ .venv / bin / aktifkan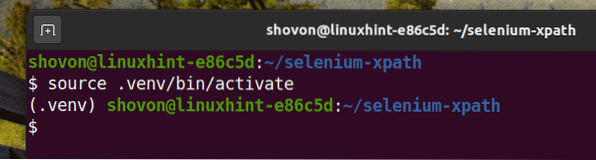
Pasang perpustakaan Selenium Python menggunakan PIP3 seperti berikut:
$ pip3 memasang selenium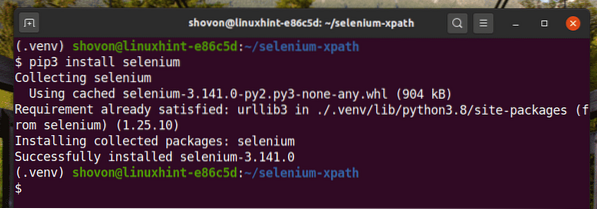
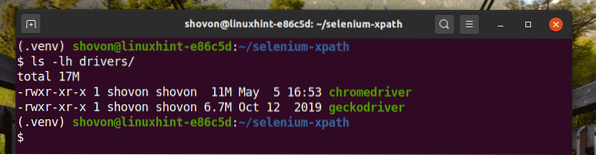
Muat turun dan pasang semua pemacu web yang diperlukan di pemandu / direktori projek. Saya telah menerangkan proses memuat turun dan memasang pemacu web dalam artikel saya Pengenalan Selenium di Python 3.
Dapatkan Pemilih XPath menggunakan Alat Pembangun Chrome:
Di bahagian ini, saya akan menunjukkan kepada anda cara mencari pemilih XPath elemen halaman web yang ingin anda pilih dengan Selenium menggunakan Alat Pembangun bawaan penyemak imbas web Google Chrome.
Untuk mendapatkan pemilih XPath menggunakan penyemak imbas web Google Chrome, buka Google Chrome, dan lawati laman web dari mana anda ingin mengekstrak data. Kemudian, tekan butang kanan tetikus (RMB) di kawasan kosong halaman dan klik Periksa untuk membuka Alat Pembangun Chrome.
Anda juga boleh menekan
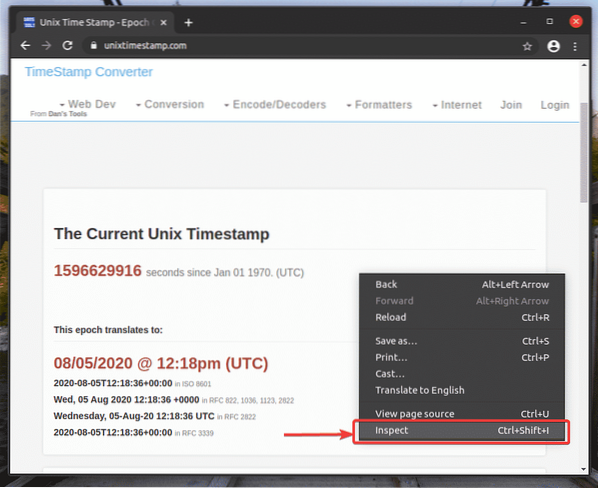
Alat Pembangun Chrome hendaklah dibuka.
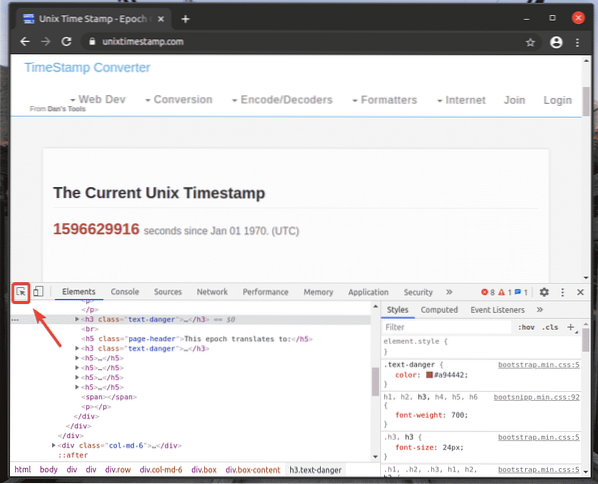
Untuk mencari representasi HTML elemen halaman web yang anda inginkan, klik pada Periksa(
), seperti yang ditunjukkan pada tangkapan skrin di bawah.
Kemudian, arahkan kursor ke elemen halaman web yang anda inginkan dan tekan butang kiri tetikus (LMB) untuk memilihnya.
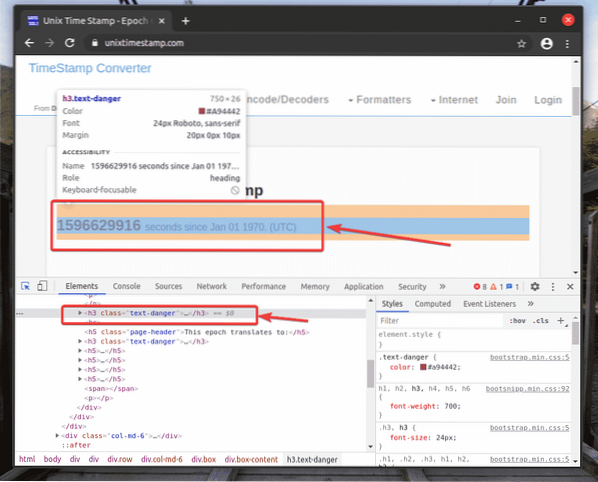
Perwakilan HTML elemen web yang anda pilih akan disorot di Unsur tab dari Alat Pembangun Chrome, seperti yang anda lihat dalam tangkapan skrin di bawah.
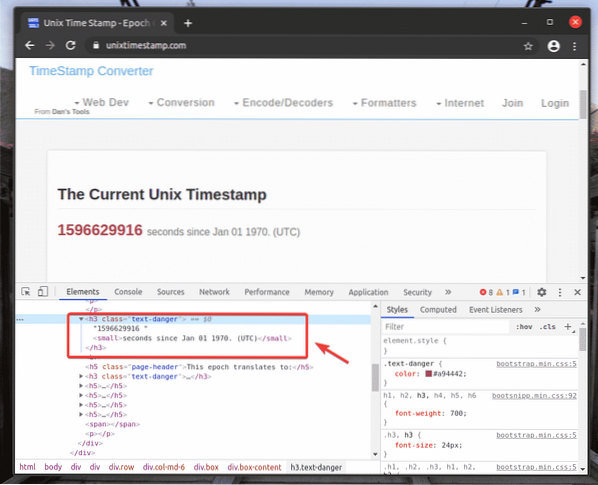
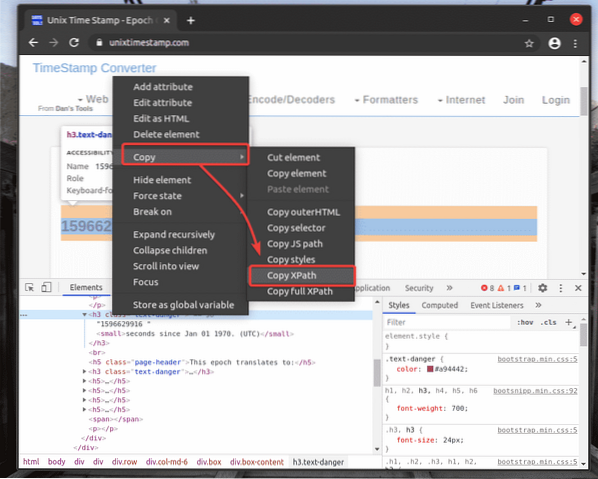
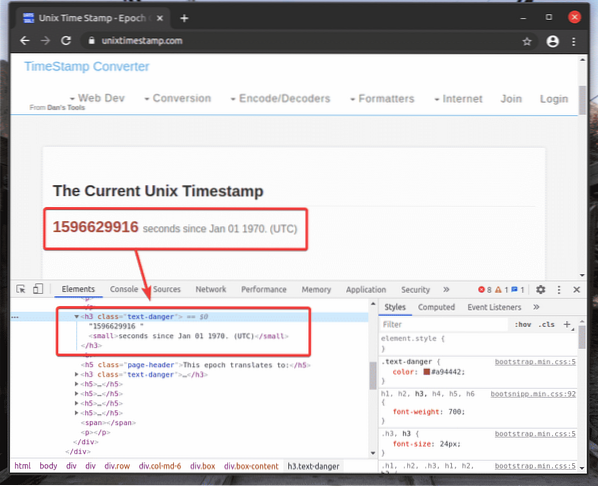
Untuk mendapatkan pemilih XPath elemen yang anda inginkan, pilih elemen dari Unsur tab dari Alat Pembangun Chrome dan klik kanan (RMB) di atasnya. Kemudian, pilih Salinan > Salin XPath, seperti yang ditandakan pada tangkapan skrin di bawah.
Saya telah menampal pemilih XPath dalam penyunting teks. Pemilih XPath kelihatan seperti yang ditunjukkan dalam tangkapan skrin di bawah.

Dapatkan Pemilih XPath menggunakan Firefox Developer Tool:
Di bahagian ini, saya akan menunjukkan kepada anda cara mencari pemilih XPath elemen halaman web yang ingin anda pilih dengan Selenium menggunakan Alat Pembangun terbina dalam pelayar web Mozilla Firefox.
Untuk mendapatkan pemilih XPath menggunakan penyemak imbas web Firefox, buka Firefox dan lawati laman web dari mana anda ingin mengekstrak data. Kemudian, tekan butang kanan tetikus (RMB) di kawasan kosong halaman dan klik Periksa Elemen (Q) untuk membuka Alat Pembangun Firefox.
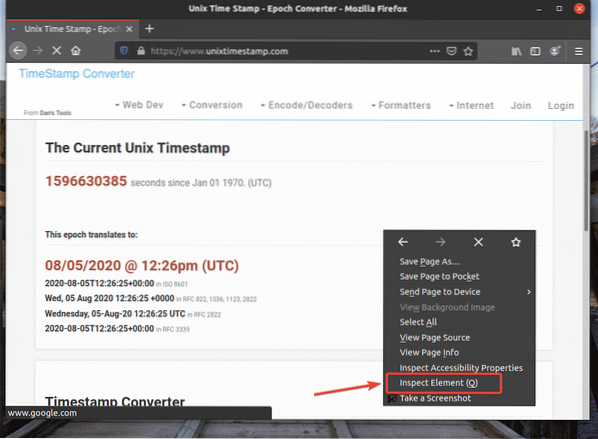
Alat Pembangun Firefox hendaklah dibuka.
Untuk mencari representasi HTML elemen halaman web yang anda inginkan, klik pada Periksa(
), seperti yang ditunjukkan pada tangkapan skrin di bawah.
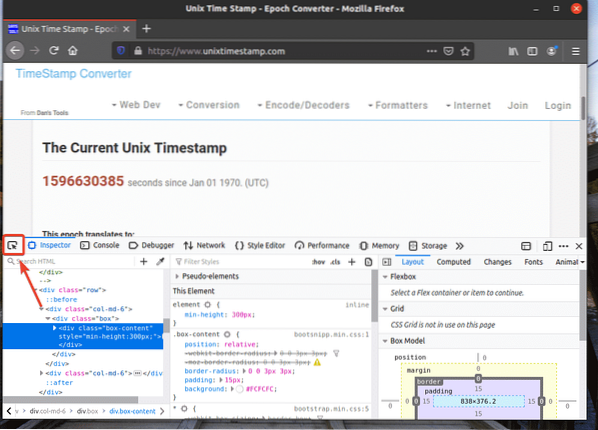
Kemudian, arahkan kursor ke elemen halaman web yang anda inginkan dan tekan butang kiri tetikus (LMB) untuk memilihnya.
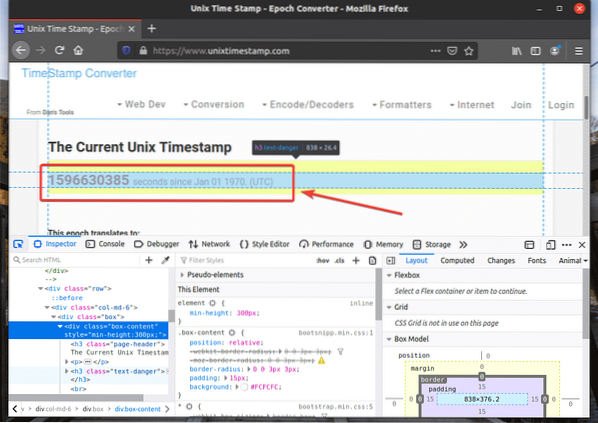
Perwakilan HTML elemen web yang anda pilih akan disorot di Pemeriksa tab dari Alat Pembangun Firefox, seperti yang anda lihat dalam tangkapan skrin di bawah.
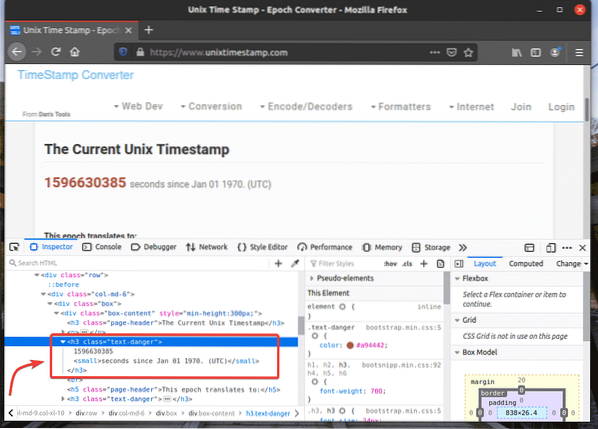
Untuk mendapatkan pemilih XPath elemen yang anda inginkan, pilih elemen dari Pemeriksa tab dari Alat Pembangun Firefox dan klik kanan (RMB) di atasnya. Kemudian, pilih Salinan > XPath seperti yang ditandakan pada tangkapan skrin di bawah.
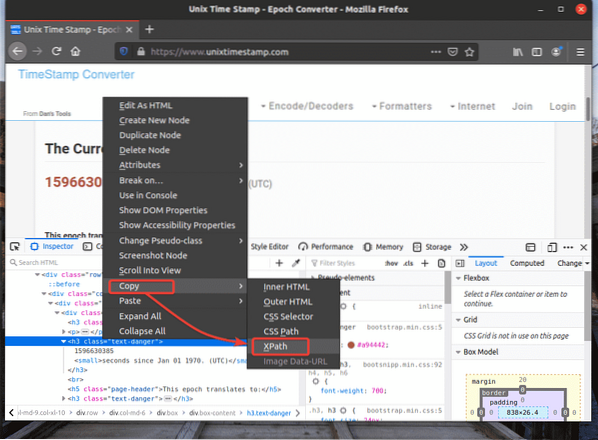
Pemilih XPath elemen yang anda mahukan akan kelihatan seperti ini.

Mengekstrak Data dari Halaman Web menggunakan XPath Selector:
Di bahagian ini, saya akan menunjukkan kepada anda cara memilih elemen halaman web dan mengekstrak data daripadanya menggunakan pemilih XPath dengan perpustakaan Selenium Python.
Pertama, buat skrip Python baru ex01.py dan taipkan baris kod berikut.
dari pemacu web import seleniumdari selenium.pemacu laman web.biasa.kunci import Kekunci
dari selenium.pemacu laman web.biasa.oleh import Oleh
pilihan = pemacu web.Pilihan Chrome ()
pilihan.tanpa kepala = Betul
penyemak imbas = pemacu web.Chrome (executable_path = "./ pemacu / chromedriver ",
pilihan = pilihan)
penyemak imbas.dapatkan ("https: // www.cap unixtimest.com / ")
cap waktu = penyemak imbas.cari_element_by_xpath ('/ html / body / div [1] / div [1]
/ div [2] / div [1] / div / div / h3 [2] ')
cetak ('Cap waktu semasa:% s'% (cap waktu.teks.berpisah (") [0]))
penyemak imbas.tutup ()
Setelah selesai, simpan ex01.py Skrip Python.
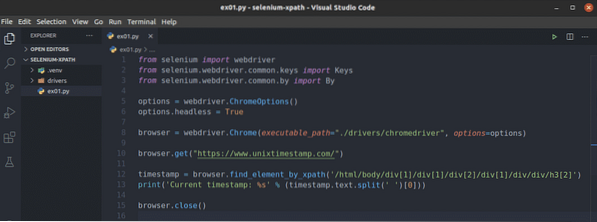
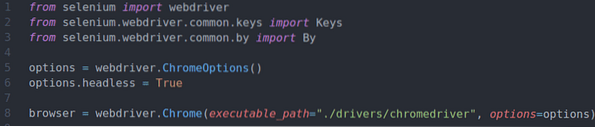
Baris 1-3 mengimport semua komponen Selenium yang diperlukan.

Baris 5 membuat objek Pilihan Chrome, dan baris 6 membolehkan mod tanpa kepala untuk penyemak imbas web Chrome.

Baris 8 membuat Chrome penyemak imbas objek menggunakan kromedriver binari dari pemandu / direktori projek.

Baris 10 memberitahu penyemak imbas memuatkan cap laman web unixtimestamp.com.

Baris 12 menemui elemen yang mempunyai data cap waktu dari halaman menggunakan pemilih XPath dan menyimpannya di cap waktu pemboleh ubah.
Baris 13 menguraikan data cap waktu dari elemen dan mencetaknya pada konsol.

Saya telah menyalin pemilih XPath yang bertanda h2 unsur dari cap unixtimest.com menggunakan Alat Pembangun Chrome.
Baris 14 menutup penyemak imbas.

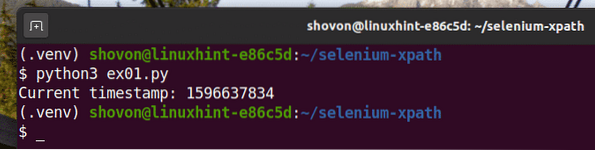
Jalankan skrip Python ex01.py seperti berikut:
$ python3 ex01.py
Seperti yang anda lihat, data cap waktu dicetak di skrin.
Di sini, saya telah menggunakan penyemak imbas.find_element_by_xpath (pemilih) kaedah. Satu-satunya parameter kaedah ini adalah pemilih, yang merupakan pemilih XPath elemen.
Bukannya penyemak imbas.cari_element_by_xpath () kaedah, anda juga boleh menggunakan penyemak imbas.find_element (Oleh, pemilih) kaedah. Kaedah ini memerlukan dua parameter. Parameter pertama Oleh akan jadi Oleh.XPATH kerana kita akan menggunakan pemilih XPath, dan parameter kedua pemilih akan menjadi pemilih XPath itu sendiri. Hasilnya akan sama.
Untuk melihat bagaimana penyemak imbas.cari_elemen () kaedah berfungsi untuk pemilih XPath, buat skrip Python baru ex02.py, salin dan tampal semua baris dari ex01.py ke ex02.py dan berubah baris 12 seperti yang ditandakan pada tangkapan skrin di bawah.
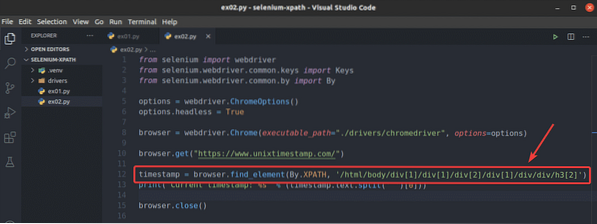
Seperti yang anda lihat, skrip Python ex02.py memberikan hasil yang sama seperti ex01.py.
$ python3 ex02.py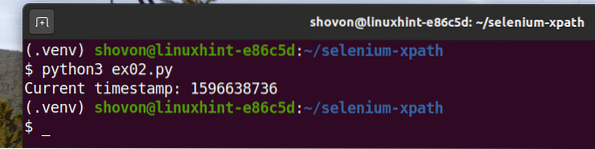
The penyemak imbas.cari_element_by_xpath () dan penyemak imbas.cari_elemen () kaedah digunakan untuk mencari dan memilih satu elemen dari laman web. Sekiranya anda ingin mencari dan memilih beberapa elemen menggunakan pemilih XPath, maka anda harus menggunakan penyemak imbas.cari_elemen_by_xpath () atau penyemak imbas.cari_ elemen () kaedah.
The penyemak imbas.cari_elemen_by_xpath () kaedah mengambil hujah yang sama dengan penyemak imbas.cari_element_by_xpath () kaedah.
The penyemak imbas.cari_ elemen () kaedah mengambil hujah yang sama dengan penyemak imbas.cari_elemen () kaedah.
Mari kita lihat contoh mengekstrak senarai nama menggunakan pemilih XPath dari penjana nama rawak.maklumat dengan perpustakaan Selenium Python.
Senarai yang tidak tersusun (ol tag) mempunyai 10 li tag di dalamnya masing-masing mengandungi nama rawak. XPath untuk memilih semua li tag di dalam ol tag dalam kes ini adalah // * [@ id = "utama"] / div [3] / div [2] / ol // li
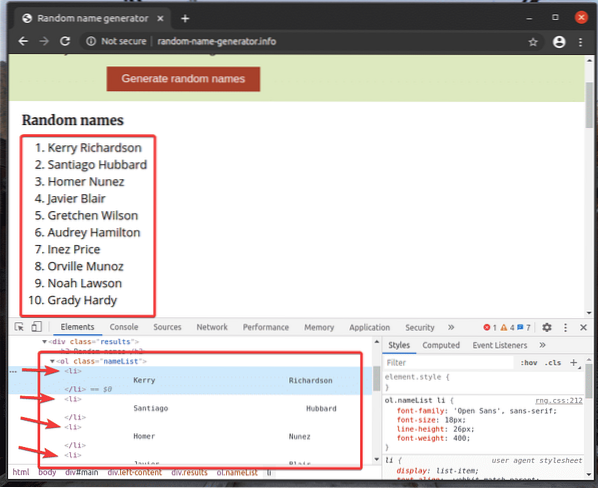
Mari kita teliti contoh memilih beberapa elemen dari laman web menggunakan pemilih XPath.
Buat skrip Python baru ex03.py dan taipkan baris kod berikut di dalamnya.
dari pemacu web import seleniumdari selenium.pemacu laman web.biasa.kunci import Kekunci
dari selenium.pemacu laman web.biasa.oleh import Oleh
pilihan = pemacu web.Pilihan Chrome ()
pilihan.tanpa kepala = Betul
penyemak imbas = pemacu web.Chrome (executable_path = "./ pemacu / chromedriver ",
pilihan = pilihan)
penyemak imbas.dapatkan ("http: // rawak-nama-penjana.maklumat / ")
nama = penyemak imbas.cari_elemen_by_xpath ('
// * [@ id = "main"] / div [3] / div [2] / ol // li ')
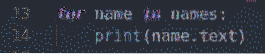
untuk nama dalam nama:
mencetak (nama.teks)
penyemak imbas.tutup ()
Setelah selesai, simpan ex03.py Skrip Python.
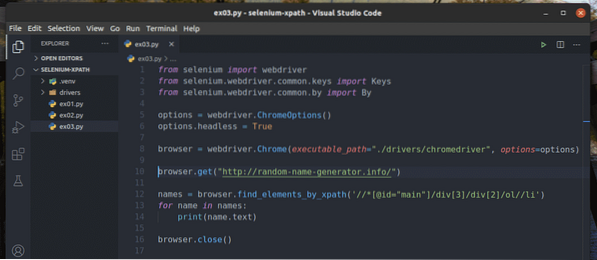
Baris 1-8 sama seperti di ex01.py Skrip Python. Jadi, saya tidak akan menerangkannya di sini lagi.
Baris 10 memberitahu penyemak imbas untuk memuatkan penjana nama rawak laman web.maklumat.

Baris 12 memilih senarai nama menggunakan penyemak imbas.cari_elemen_by_xpath () kaedah. Kaedah ini menggunakan pemilih XPath // * [@ id = "main"] / div [3] / div [2] / ol // li untuk mencari senarai nama. Kemudian, senarai nama disimpan di nama-nama pemboleh ubah.

Dalam baris 13 dan 14, a untuk gelung digunakan untuk melakukan lelaran melalui nama-nama senaraikan dan cetak nama pada konsol.
Baris 16 menutup penyemak imbas.

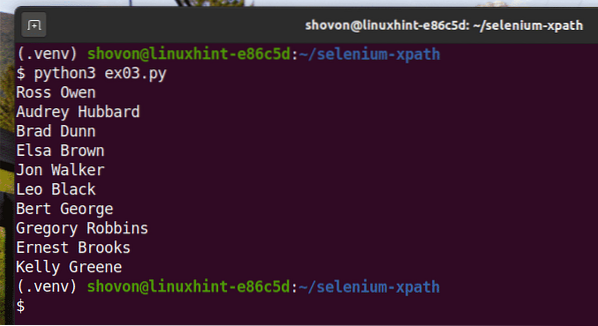
Jalankan skrip Python ex03.py seperti berikut:
$ python3 ex03.py
Seperti yang anda lihat, nama-nama tersebut diekstrak dari laman web dan dicetak di konsol.
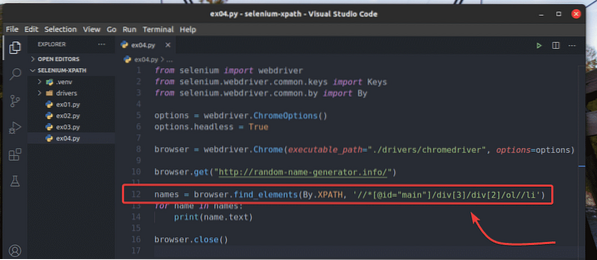
Daripada menggunakan penyemak imbas.cari_elemen_by_xpath () kaedah, anda juga boleh menggunakan penyemak imbas.cari_ elemen () kaedah seperti sebelumnya. Hujah pertama kaedah ini adalah Oleh.XPATH, dan hujah kedua adalah pemilih XPath.
Untuk bereksperimen dengan penyemak imbas.cari_ elemen () kaedah, buat skrip Python baru ex04.py, salin semua kod dari ex03.py ke ex04.py, dan ubah baris 12 seperti yang ditandakan pada tangkapan skrin di bawah.
Anda harus mendapat hasil yang sama seperti sebelumnya.
$ python3 ex04.py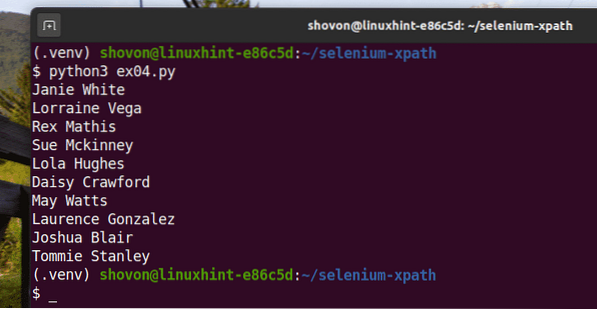
Asas Pemilih XPath:
Alat Pembangun Firefox atau penyemak imbas web Google Chrome menghasilkan pemilih XPath secara automatik. Tetapi pemilih XPath ini kadangkala tidak mencukupi untuk projek anda. Sekiranya demikian, anda mesti tahu apa yang dilakukan oleh pemilih XPath tertentu untuk membina pemilih XPath anda. Dalam bahagian ini, saya akan menunjukkan kepada anda asas-asas pemilih XPath. Kemudian, anda seharusnya dapat membina pemilih XPath anda sendiri.
Buat direktori baru www / dalam direktori projek anda seperti berikut:
$ mkdir -v www
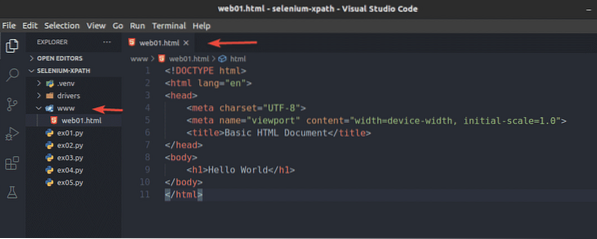
Buat fail baru laman web01.html di dalam www / direktori dan ketik baris berikut dalam fail itu.
Hai dunia
Setelah selesai, simpan laman web01.html fail.
Jalankan pelayan HTTP sederhana pada port 8080 menggunakan arahan berikut:
$ python3 -m http.pelayan --direktori www / 8080
Pelayan HTTP harus bermula.
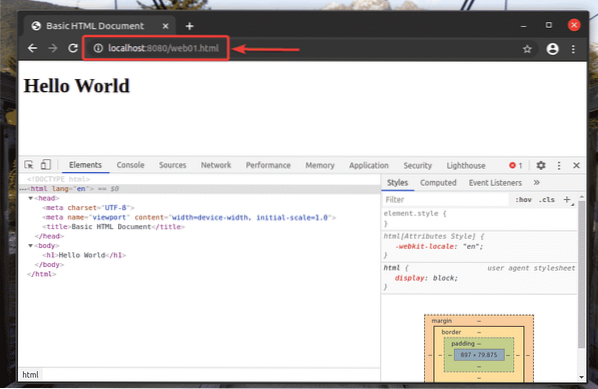
Anda seharusnya dapat mengakses laman web01.html fail menggunakan URL http: // localhost: 8080 / web01.html, seperti yang anda lihat dalam tangkapan skrin di bawah.
Semasa Firefox atau Chrome Developer Tool dibuka, tekan
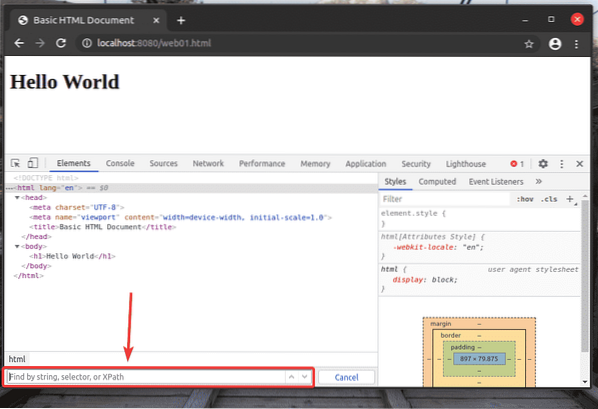
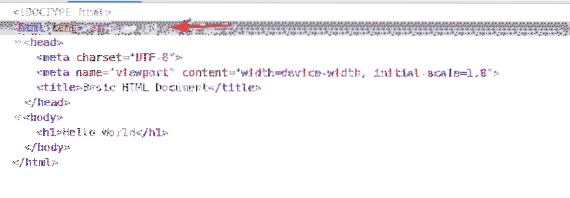
Pemilih XPath bermula dengan a garis miring ke hadapan (/) selalunya. Ia seperti pokok direktori Linux. The / adalah akar semua elemen di laman web.
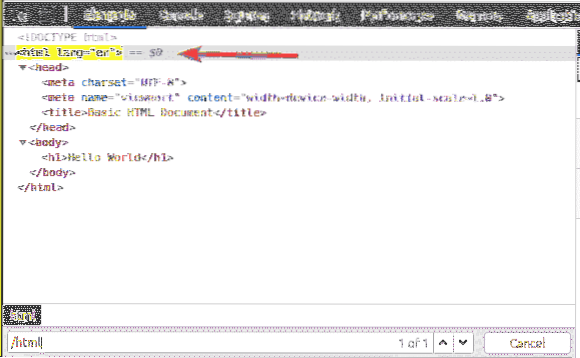
Elemen pertama ialah html. Jadi, pemilih XPath / html memilih keseluruhan html teg.
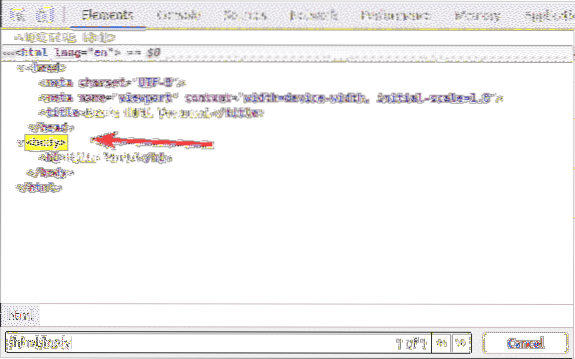
Di dalam html tag, kami mempunyai badan teg. The badan tag boleh dipilih dengan pemilih XPath / html / badan
The h1 header berada di dalam badan teg. The h1 header boleh dipilih dengan pemilih XPath / html / badan / h1
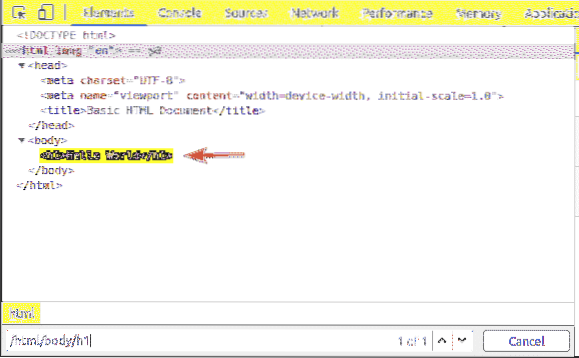
Pemilih XPath jenis ini dipanggil pemilih jalur mutlak. Dalam pemilih jalur mutlak, anda mesti melintasi halaman web dari akar (/) halaman. Kelemahan pemilih jalur mutlak adalah bahawa walaupun sedikit perubahan pada struktur halaman web dapat menjadikan pemilih XPath anda tidak sah. Penyelesaian untuk masalah ini adalah pemilih XPath relatif atau separa.
Untuk melihat bagaimana jalan relatif atau jalan separa berfungsi, buat fail baru laman web02.html di dalam www / direktori dan ketik baris kod berikut di dalamnya.
Hai dunia
ini adalah mesej
Hai dunia
Setelah selesai, simpan laman web02.html fail dan muatkan di penyemak imbas web anda.
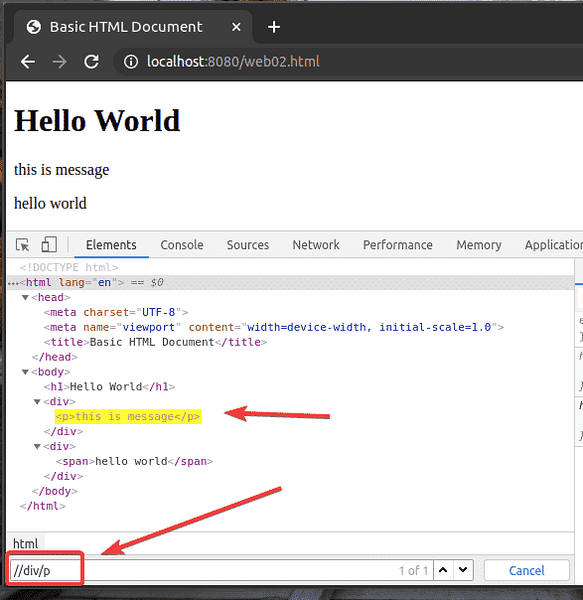
Seperti yang anda lihat, pemilih XPath // div / p memilih hlm tag di dalam div teg. Ini adalah contoh pemilih XPath relatif.
Pemilih XPath relatif bermula dengan //. Kemudian anda menentukan struktur elemen yang ingin anda pilih. Dalam kes ini, div / p.
Jadi, // div / p bermaksud pilih hlm unsur di dalam a div unsur, tidak kira apa yang berlaku sebelum itu.
Anda juga boleh memilih elemen dengan atribut yang berbeza seperti ID, kelas, menaip, dan lain-lain. menggunakan pemilih XPath. Mari lihat bagaimana melakukannya.
Buat fail baru laman web03.html di dalam www / direktori dan ketik baris kod berikut di dalamnya.
Hai dunia
ini adalah mesej
ini adalah mesej lain
tajuk 2
Lorem ipsum dolor sit amet consectetur, menyesuaikan elit. Quibusdam
elendi doloribus sapiente, molestias quos quae non nam incidunt quis delectus
fasilis magni officiis alias neque atque fuga? Unde, aut natus?
Setelah selesai, simpan laman web03.html fail dan muatkan di penyemak imbas web anda.
Katakan anda mahu memilih semua div unsur yang mempunyai kelas nama bekas1. Untuk melakukannya, anda boleh menggunakan pemilih XPath // div [@ class = 'container1']
Seperti yang anda lihat, saya mempunyai 2 elemen yang sesuai dengan pemilih XPath // div [@ class = 'container1']
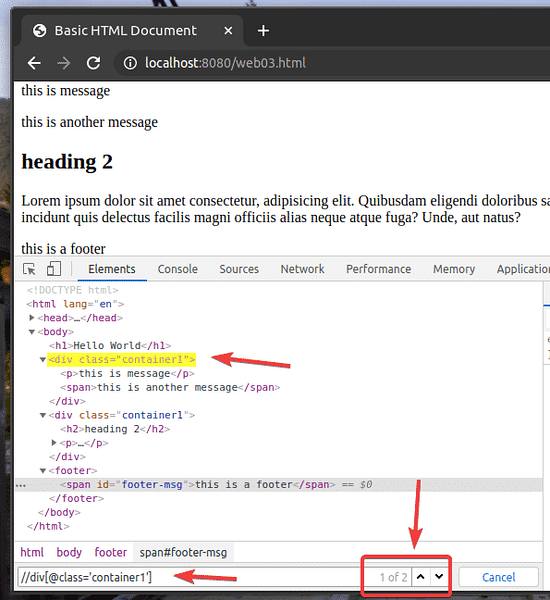
Untuk memilih yang pertama div unsur dengan kelas nama bekas1, Tambah [1] pada akhir pilih XPath, seperti yang ditunjukkan dalam tangkapan skrin di bawah.
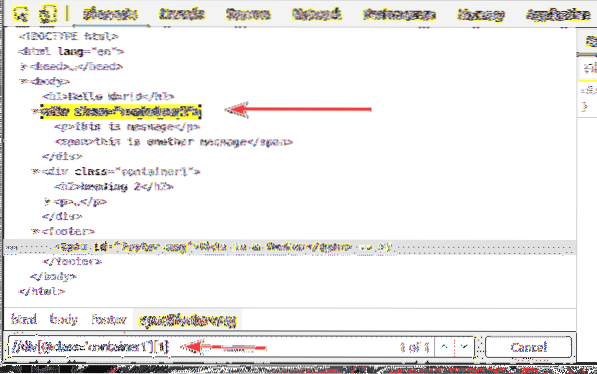
Dengan cara yang sama, anda boleh memilih yang kedua div unsur dengan kelas nama bekas1 menggunakan pemilih XPath // div [@ class = 'container1'] [2]
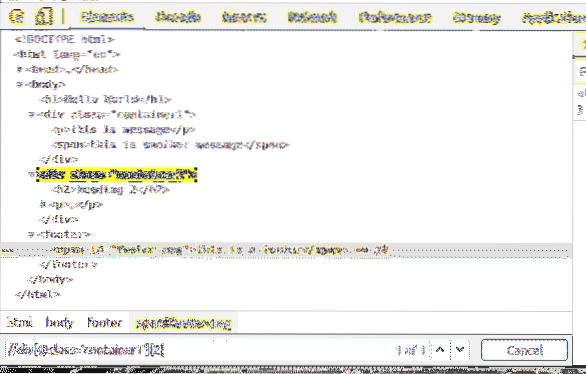
Anda boleh memilih elemen dengan ID juga.
Sebagai contoh, untuk memilih elemen yang mempunyai ID daripada footer-msg, anda boleh menggunakan pemilih XPath // * [@ id = 'footer-msg']
Di sini, * sebelum ini [@ id = 'footer-msg'] digunakan untuk memilih elemen apa pun tanpa mengira tagnya.
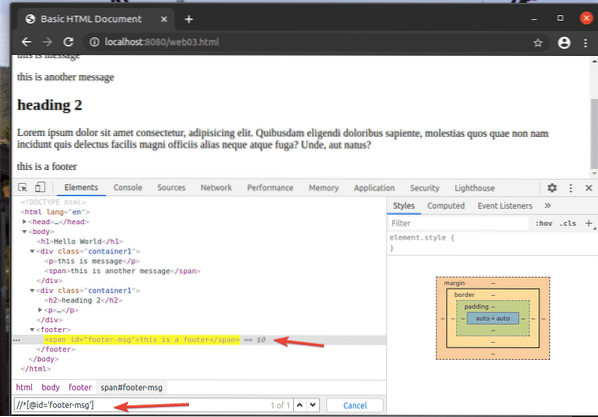
Itulah asas pemilih XPath. Sekarang, anda seharusnya dapat membuat pemilih XPath anda sendiri untuk projek Selenium anda.
Kesimpulan:
Dalam artikel ini, saya telah menunjukkan kepada anda cara mencari dan memilih elemen dari laman web menggunakan pemilih XPath dengan perpustakaan Selenium Python. Saya juga telah membincangkan pemilih XPath yang paling biasa. Setelah membaca artikel ini, anda pasti merasa yakin memilih elemen dari laman web menggunakan pemilih XPath dengan perpustakaan Selenium Python.


